在我的上篇Blog中,介绍了Seedbox环境中的下载工具的搭建过程。但其实我们还有一个需求:就是将文件从盒子空间中拖回本地。如果你详细的看了上文,并能认真理解我最后写的Nginx配置,你就会发现我注释了一个一直也没创建也没说明的文件#include snippets/download.conf;
常见的取回方法有以下几类:SFTP、FTP、HTTP、BTSync等,我个人喜欢使用前三类。当然你也可以考虑使用网盘中转,将文件从盒子中首先上传到第三方网盘,再从网盘中取回(常用的网盘服务有Google Drive、OneDrive)。
个人对SFTP和FTP的感觉差不多,但两者均没有合适的本地客户端来提供多线程分片下载的功能(IDM事实上是提供类似支持的),但是可以通过多进程的方式来实现多文件同时下载的能力,SFTP比FTP较为简单的是直接基于SSH服务,无需另外安装其他服务。HTTP因为具有分片下载的能力,但多文件同时下载较为麻烦,特别是出现文件夹嵌套的情况。同时对于盒子空间在国外的用户,使用HTTP下载可以利用上Cloudflare的CDN加速(如果你有域名的话,(随便申一个免费的23333))
我个人喜欢的方法是 单文件或多文件无文件夹层级 - HTTP;多文件有文件夹层级 - SFTP或FTP
HTTP
在上一篇下载安装中,我使用了Nginx作为Web服务器。
Nginx默认是不允许列出整个目录的。如需此功能,打开nginx.conf文件或你要启用目录浏览虚拟主机的配置文件,在server或location 段里添加上autoindex on;来启用目录流量,下面是rtinst使用的配置,将其直接放在snippets/download.conf中并取消原有注释,即可轻松使用。
1 | location ~ ^/download/(.+?)(/.*)?$ { |
在这个配置中,可以在域名的download文件夹下访问目标用户主目录。
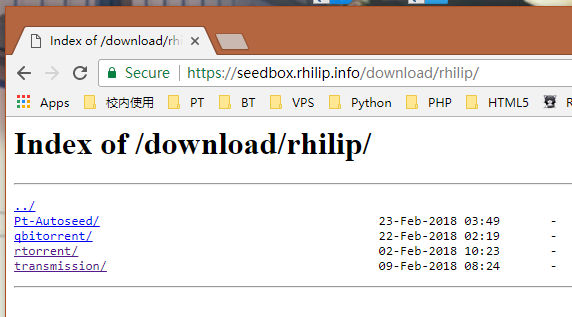
但是默认的目录流量页面可能过于丑陋,喜欢美观的可以使用fancyindex模块做进一步优化。这也就是我们在安装nginx时候使用nginx-extra包的原因。
关于nginx-*包的区别可以查看该问答:What is the difference between the core, full, extras and light packages for nginx? - Ask Ubuntu
我比较喜欢的两个Nginx-Fancyindex-Theme如下:
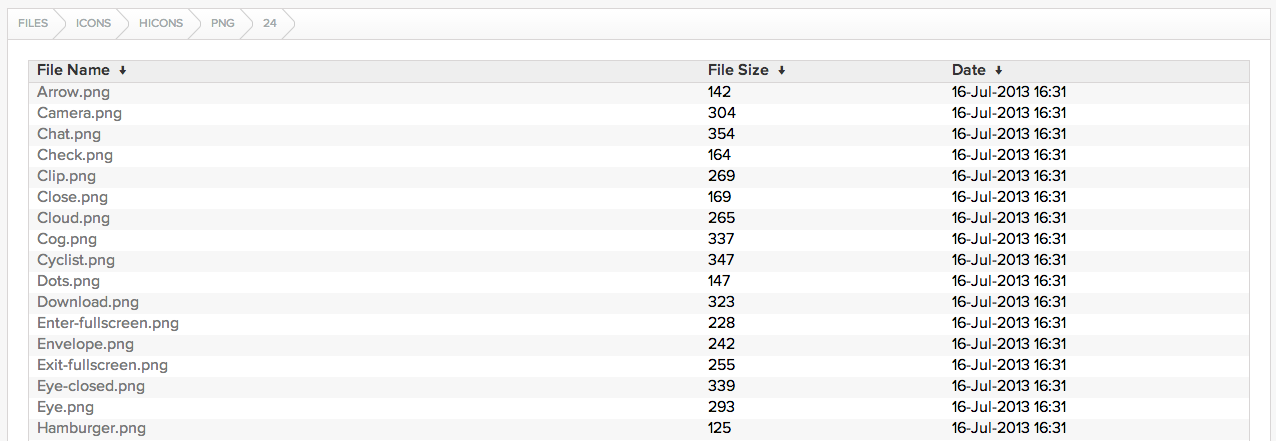
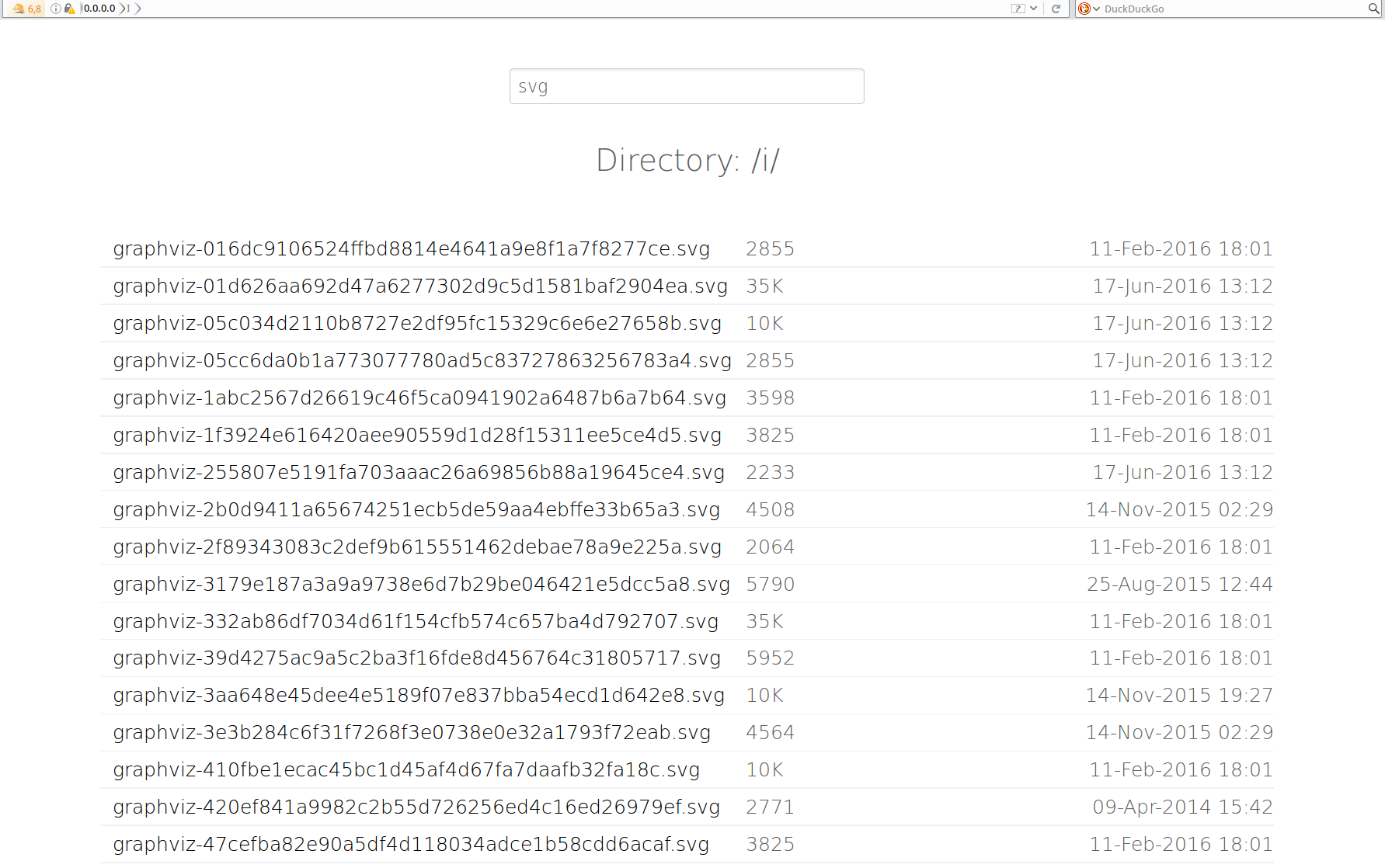
其他的你可以使用Nginx-Fancyindex-Theme作为关键词在Github上搜索。
按照对应的README.md下载文件到网站根目录下,并修改原有的下载文件配置就可。
注:nginx-extra包自带的fancyindex模块可能不支持
fancyindex_name_length 255;配置项(,即对于过长的文件名会使用…替换过长字符)。如果需要,请下载nginx及ngx-fancyindex进行编译替换2333333
SFTP
无需过多设置,建议使用FileZilla这款同时支持SFTP与FTP的工具来登陆。
FTP
FTP的客户端程序我比较喜欢使用pure-ftpd,因为可以同时监听IPv4和IPv6地址。而vsftpd并不能做到同时监听(如果要同时监听的话,需要使用两份不同的配置文件,一份监听IPv4,一份监听IPv6,并启用)
从包管理器安装也十分方便:apt-get install pure-ftpd
相应的系统管理命令有:
1 | systemctl status pure-ftpd.service |
添加虚拟用户请用pure-pw命令,如pure-pw useradd rhilip -u rhilip -g rhilip -d /home/rhilip就添加了一个登陆用户名为rhilip,根目录为/home/rhilip的用户。
之后使用pure-pw mkdb更新数据库即可。
之后就可以轻松的使用FileZilla来登陆了(●ˇ∀ˇ●)
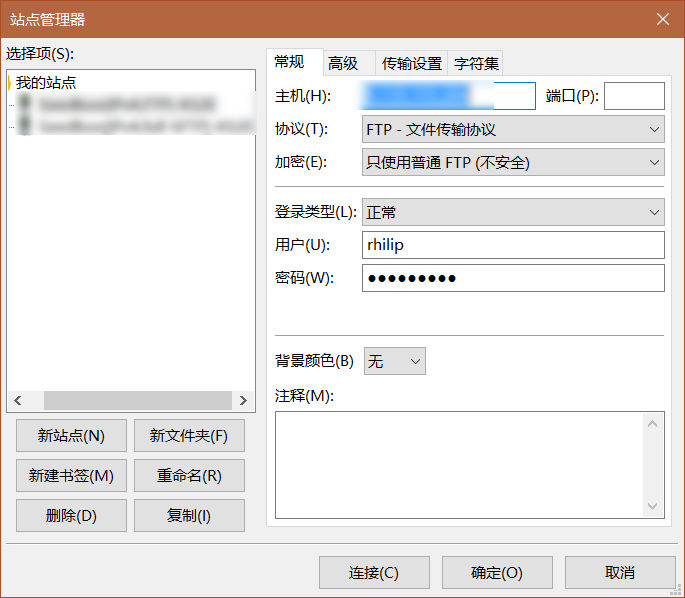
关于FTP启用TLS(即FTPS),请随意Google相关教程吧。比如:SETUP PURE-FTPD ON UBUNTU 16.04 LTS WITH SSL/TLS CERTIFICATES