在使用Manifest v3规范编写浏览器插件 PT-Depiler 时,我们发现插件在获取部分站点信息时会失败。
进一步 debug 可知,这些站点启用了跨站请求伪造 (CSRF) 保护,即通过验证 Origin 请求头,并拒绝相关插件的请求。
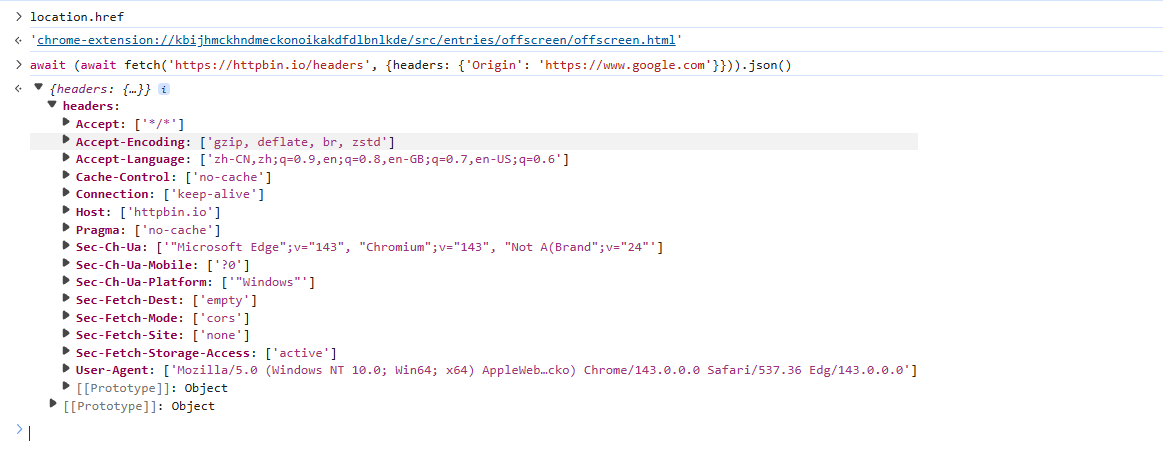
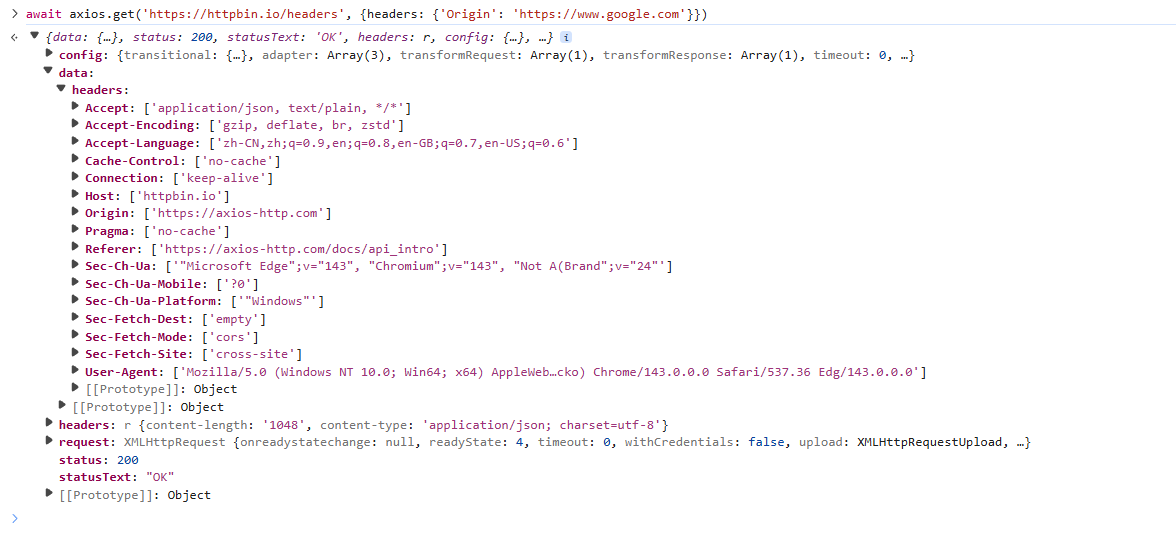
然而 Origin 请求头并不能由插件直接控制,当插件在从 offscreen 或者 service worker 等环境下发起 fetch 或 xmlhttprequest 请求时,浏览器会自动将该请求的 Origin 标头设置为你的扩展程序的来源 (origin),即: Origin: chrome-extension://[YOUR_EXTENSION_ID]。

这一请求头甚至都不能覆写,如果尝试在 fetch 或者 axios (指 XMLHttpRequest ) 的请求参数中手动设置 Origin,浏览器在多数情况下会静默忽略,或者直接报错。
Manifest v2 下的处理
在 Manifest v2 环境下,我们可以使用 webRequest + webRequestBlocking 权限给予 block 功能,利用类似下面代码在浏览器发送请求头之前实现对覆盖。
1 | const gDummyHeaderPrefix = "Overwrite-"; |
这段代码注册了一个监听器拦截所有网址的网络请求,其中 blocking 参数表示这是「阻塞式监听」—— 浏览器会暂停发送请求,等待监听器处理完请求头后,再继续执行发送操作(确保修改后的请求头能被使用);而 extraHeaders 参数允许访问和修改 Chrome 默认保护的「敏感请求头」 (即我们所需要的 Origin、Referer 等请求头)。
Manifest v3 下的处理
然而在 Manifest v3 下,我们并不能使用 webRequestBlocking 权限,MV3的 文档 中明确指出了这一权限仅适用于通过策略安装的插件,而对于通过商店或者解压缩等方式安装的插件并不适用。
Note: As of Manifest V3, the “webRequestBlocking” permission is no longer available for most extensions. Consider “declarativeNetRequest”, which enables use the declarativeNetRequest API. Aside from “webRequestBlocking”, the webRequest API is unchanged and available for normal use. Policy installed extensions can continue to use “webRequestBlocking”.
在进一步了解 declarativeNetRequest API时,我发现 Google Group chromium-extensions 中提供了一种简易绕过方法。
1 | chrome.runtime.onInstalled.addListener(async () => { |
上面那段代码提供了一个很简单的实现,直接将插件发出的 post 请求中的 Origin 都移除。这个办法很好,稍微拓展下,比如在 requestMethods 中添加 get 或其他请求方法,即可以覆盖更多的应用场景。
但是,我们有个问题就是在 PT-Depiler 设计思路中,插件主体和站点请求 ( pkg/site 包的具体实现) 是尽可能解耦分离的,同时具体站点请求可能对 Origin 等浏览器保护头的改动(或删除)需求不一致,需要一种更为合理的方式来解决。
鉴于我们主要使用 axios 来实现网络请求,所以主要解决思路是 使用 axios 提供的拦截器在请求发送前生成DNR规则,在请求完成时删除对应的DNR规则 。
- 构造 Axios 拓展
1 | import type { AxiosInstance } from "axios"; |
因为此处的 axios 主要在 offscreen 或者 contentScript 等环境中使用,不一定能访问 chrome.declarativeNetRequest 这个 API,所以要使用 sendMessage
- 在 server worker / background 中抛出 DNR 相关处理方法
1 | import { onMessage } from "@/messages.ts"; |
此处,我们使用 updateSessionRules 而不是 updateDynamicRules ,因为 相关请求是一次性的,我们没必要保持。
Dynamic rules persist across browser sessions and extension upgrades.
Session rules are cleared when the browser shuts down and when a new version of the extension is installed.
如此,我们只要在使用 axios 前先应用这一插件,就可以让相关请求能够实现改写 Origin 的功能
1 | import axiosRaw from "axios"; |