tkinter和pyinstaller初尝 : 国自然结题报告下载工具 视窗化改造
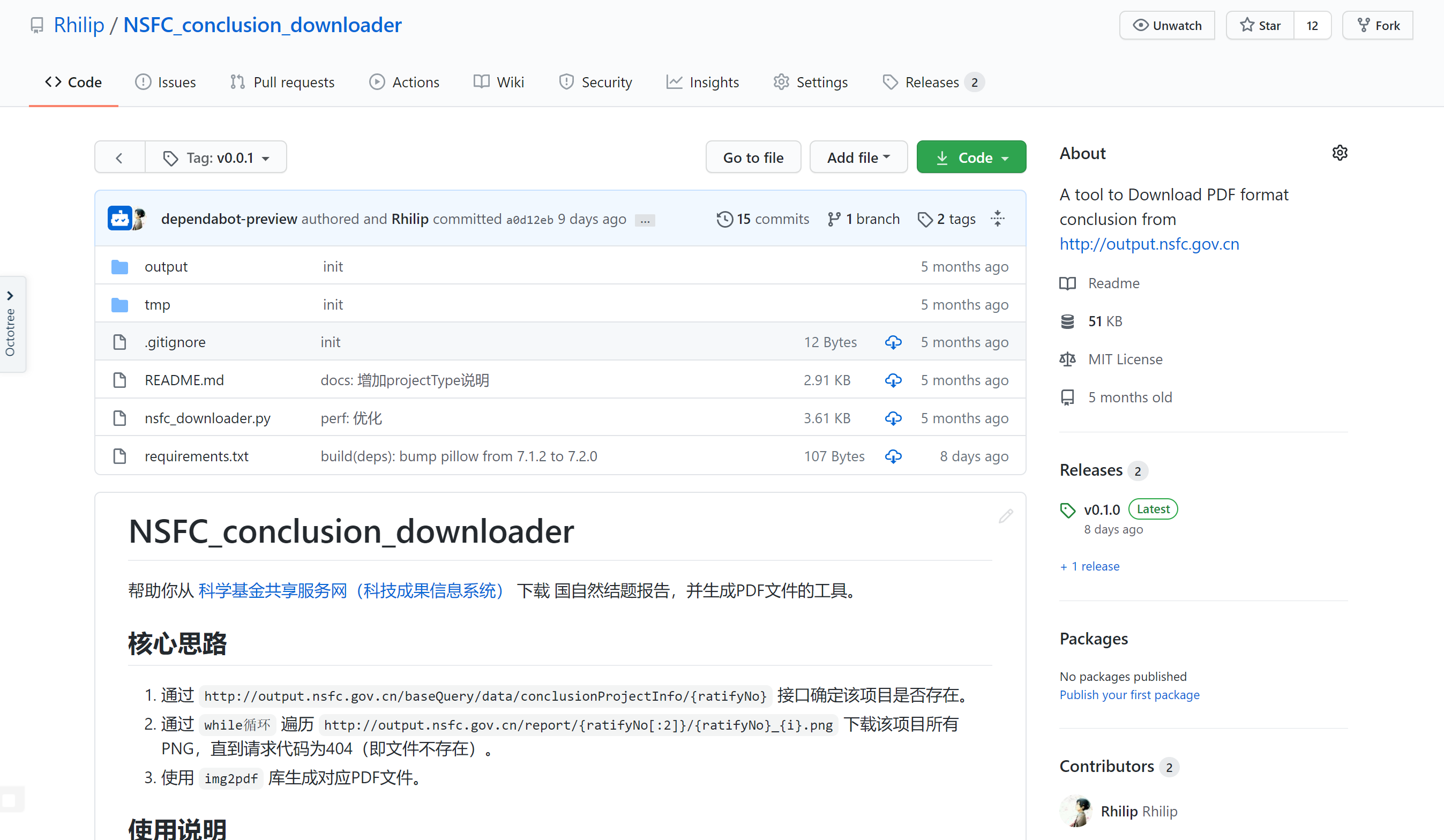
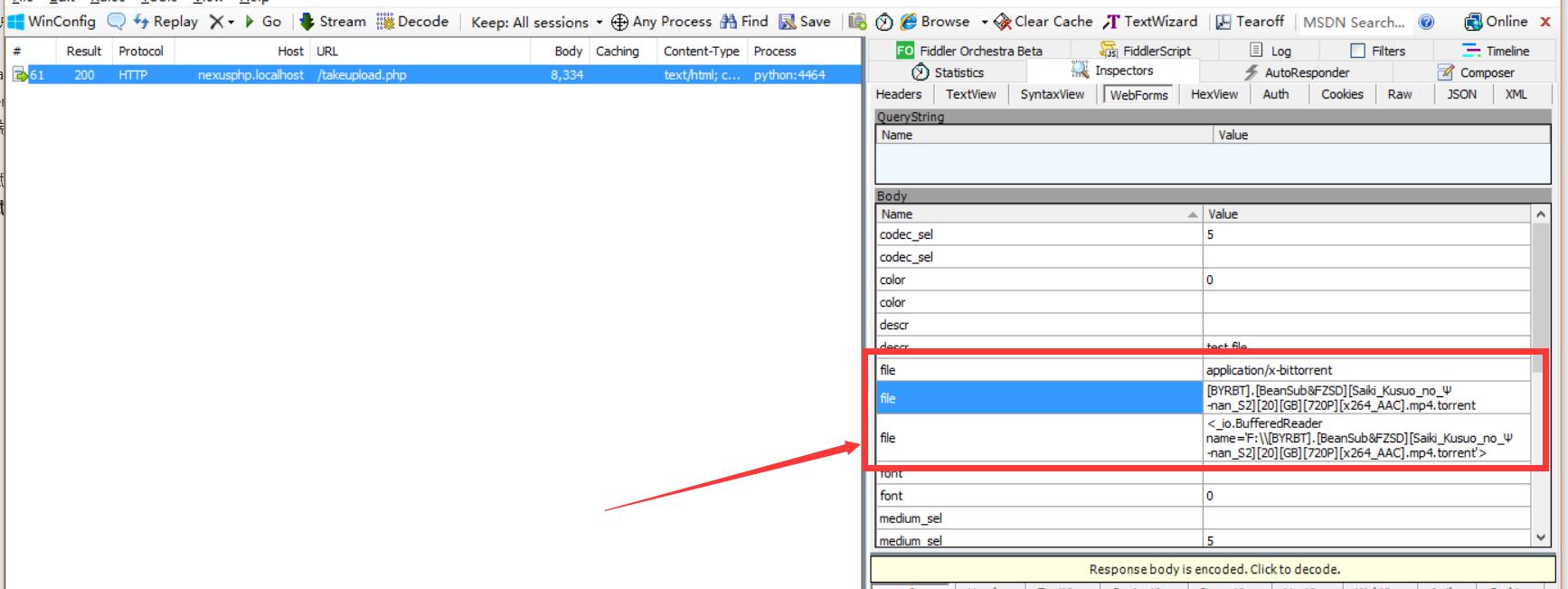
我在今年2月的时候写了个 Rhilip/NSFC_conclusion_downloader 来辅助我从科学基金共享服务网(科技成果信息系统) 下载 国自然结题报告,并生成PDF文件。截至目前也有了12个star,并且在知乎上介绍之后,也开始有其他使用的人。可毕竟原项目需要一定的python基础(基础到极限了),但使用人(包括我们课题组的同学)多数并不具备编程基础,导致原脚本形式的repo难...
Python
2020-07-09 PM


Python下载国自然结题报告 + 初尝Vue项目构建
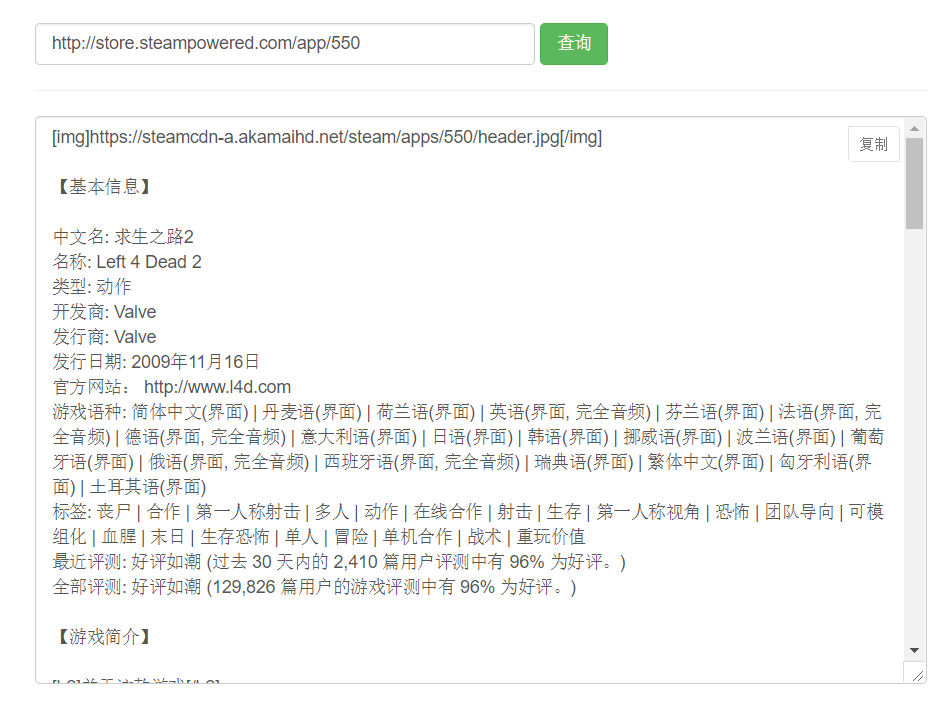
前段时间,我导师布置任务,让我根据一些关键词主题以及接下去的工作任务查找国自然的一些项目,看看其他人的科研经验。然而假期嘛~ 所以直到前几天老师打电话催问的时候,我才想起来做。为了体现工作量,我认真找了下相关课题,并准备把 科学基金共享服务网(科技成果信息系统) 上其结题报告下载了下来。在此期间,从Google、GitHub等处均搜索了相关方法,感觉都不是很好,所以自己写了个脚本。其实本文章...
Python,Javascript,Knowledge
2020-02-05 PM

栏目分类
博主动态 ~
7月初,OneDrive封了一批A1的账号,个人之前备份的仓库很多也受牵连,索性就直接不做了。 相关可见他人博客讨论: https://luotianyi.vc/4151.html2020年07月23日 18:31:21
经过一些考虑,把原来Vultr上的Blog迁移到虚拟主机上。但不知道为什么原来的主题一直出现问题,所以重新找了个主题,来自 [echo](https://www.echo.so/)。(最近也没时间看typecho的文档,所以也没空自己写,更何况原来的主题就是从别人那里找个慢慢改的)2020年02月11日 21:30:22