
最近写Autoseed的人真多,我就抛砖引玉的讲讲Python的实现吧。但是其实并不是只有Python才能实现,只要该语言具有网络通信以及本地文件读写的能力均可以。(比如某人的就是用Node.js)
传统发种流程
在介绍Autoseed的流程前,我们先回顾下传统的发种流程。。
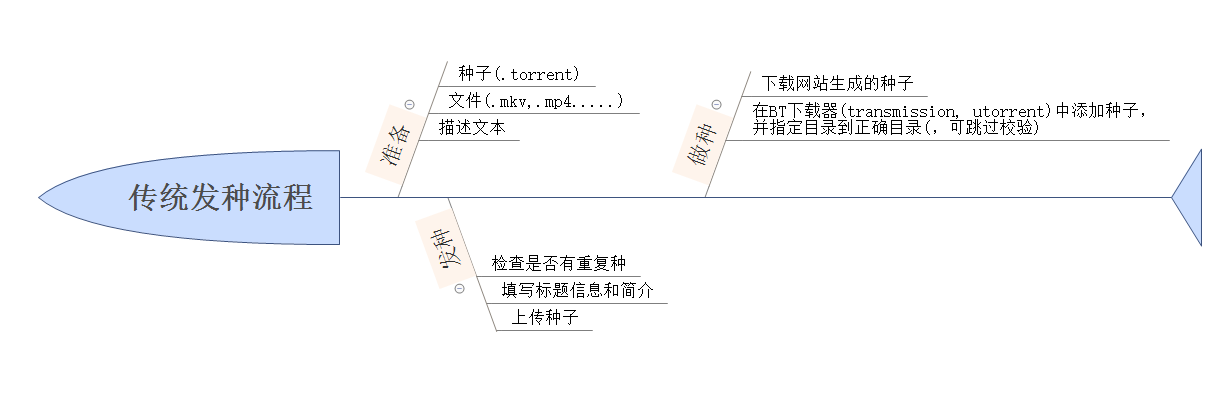
可以看到,我们需要先要在本地存在你想要自动发布的文件,并准备好发种表单需要的信息。完成发布后需要下载对应种子,以及做种软件中正确做种即可。
所以我们的自动发种程序只要模拟这个过程即可了~ (是吧是吧,多简单
序言
本来在PT站发种就不是一件简单的事,想要自动发种就更存在问题了。比如,
- 种子资源从那里获取?(上游PT站点、BT网络,自抓取);如果种子资源不是自抓取的,那么使用什么方法获取?(flexget,irssi-autodl;torrent文件还是magnet连接)
- 简介如何生成?(数据库、自引用)
- 发种表单中那些是需要根据转发种子信息修改的?(季度信息,副标题)
- 如果将表单模拟发送到站点?又使用什么方法向bt做种软件添加新种子?(watch-dir,rpc,web-api)
如果你都有点思路了,欢迎看下本人已有的开源实现 Rhilip/Pt-Autoseed。(广告:欢迎watch、star、fork、pr)
额(⊙﹏⊙) ,如果不能一下子看懂的话,可以看下最早的一次commits 6b4fb88/autoseed.py,至少那时候还稚嫩,而且单文件的逻辑比较好理清。
其他实现: https://github.com/rachpt/AutoSeed
后面我会以 Ubuntu + Python3 + Transmission 环境介绍整个过程。
种子资源从那里获取?
自抓取
如何自抓取资源不再本文的讨论范围,但是如果是自抓取来源的话,如何制作/修改种子文件应该是首先要考虑的问题。特别是对于某些0day解压包的情况。
Linux平台上比较有名的制作种子的工具是mktorrent,使用sudo apt-get install mktorrent即可安装,之后就可以用Python的subprocess库,或者os.system来调用。如下是在Shell下使用mktorrent生成种子的命令:
1 | mktorrent -v -p -a http://tracker.url -o filename.torrent folder_name |
当然,也有封装好的python-mktorrent库,仔细找找就行~
注意以下几点就行了:
- 多数NexusPHP站点不支持无Tracker项的种子,所以一定要添加一个任意的Tracker地址项。
- 种子名(-o 后第一项)中可以不添加
.torrent,如果没有,会自动添加的。 - 种子名和目录名中如果有空格字符,请使用双引号
""包裹。目录名这里如果填入的是具体文件,则会对单一文件做种。
Flexget
超级成熟的RSS订阅软件。而且支持watch、transmission-rpc等多种添加方法。在这里就不献丑了。我就说下订阅列表处理的问题。(因为有人问过)
如果是国外站点订阅欧美剧集,可以使用series模块,配合qualities和set项可以对剧集质量进行筛选。此外需要注意的是,series模块默认是不下载season pack的,需要额外添加season_packs: yes项才可以。
如果是其他类型站点订阅,个人比较建议使用RSS链接获取全部链接(而不是使用某些RSS源提供的search方法),再使用Regexp模块进行正则筛选。
此外请注意,使用Flexget接受magnet链接并通过transmissionrpc方式向transmission添加种子的方式,会使得生成的种子文件中缺少tracker项,部分站点无法正确上传。
2019.02.25注 你可以考虑对magent生成的种子文件进行修改来实现一颗带有空announce项的种子。
irssi-autodl
irssi-autodl 一般会配合rtorrent来操作(虽然不是必须的),如果要使用其他软件进行下载操作则使用watch目录进行操作(设置Action行为为Save to watch Folder.)。
简介如何生成
种子简介一般是较为重要的一环,解决方法主要是数据库存储、引用(自引用、他站引用)及自生成。
数据库存储
对于发种表单较为简单的站点,如果发种类别较为单一,使用数据库简单管理较为方便。如本人第一版就是使用数据库对发种表单所有的信息以数据库形式存储(参见Pt-Autoseed/sql/tv_info.data_only.sql)
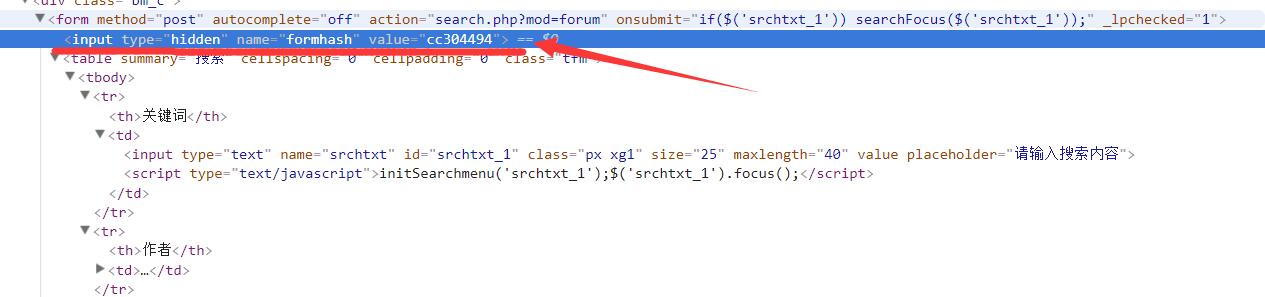
另外对于某些站点,直接搜索较为麻烦,比如六维空间(6V,非NexusPHP构架站点)搜索界面启用了csrf认证(已一个隐藏的input的hash值)。你需要先获取该值,然后构造搜索字典使用post方法提交,此外该站点限制了搜索间隔(30s)。搜索较为麻烦。
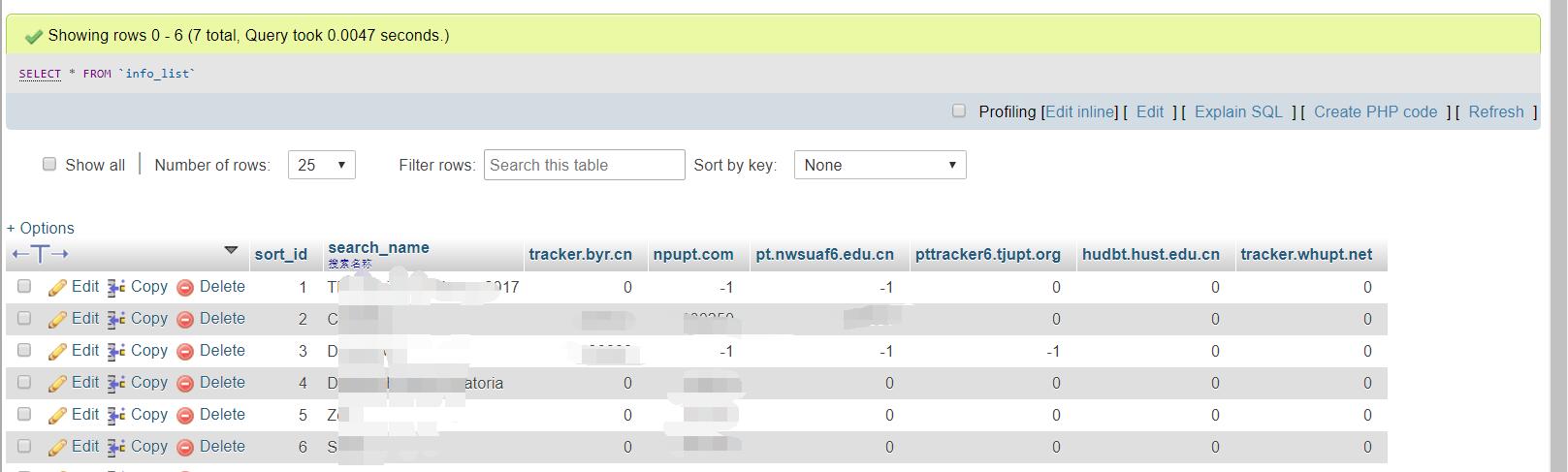
经过几次重构,本人目前已经转用自引用方式生成简介信息。但是在数据库及相关发种逻辑中保留了数据库存储的方法。但是因为需要面对多站发布的情况。目前存储的已经不是实际的发种表单信息,而是各站的“参考”引用种子号。同时可以对各站不需要发布的种子进行-1标记。
自引用
通过搜索对应种子在目标站点可以供引用的种子信息,可以从已有种子的信息中分析得到可供发种表单使用的信息。目前本人就采用这种方法。
部分站点提供API形式的自引用接口,如西农麦田pt站点的对应的接口网址为:https://pt.nwsuaf6.edu.cn/citetorrent.php?torrent_id={tid} ,所有发种表单信息均可从中得到。

对于部分不提供API的站点,也可以采取读取/details.php?id={tid}页面进行分析,如果发种表单为bbcode格式,因为NexusPHP系对于bbcodeparser的处理较为简单,可直接使用html2bbcode库将原有简介信息转化为bbcode格式。如下示例代码。
1 | import requests |
自生成
这一块不是指根据种子内容修改简介,而是指直接“凭空”生成所有简介信息。同时这一块仅作抛砖引玉,不排除有其他方法。(因为我自己都没用过。。。。
下面介绍两种已经较为成熟的实现
- 使用种子文件名的关键信息(如剧名、季度)通过豆瓣API、Bangumi公开API的搜索功能搜索出相应的douban、Bangumi号,然后(使用movieinfogen等工具)生成对应简介
- 参考示例: Byrbt - Get Movie Info Directly.user.js
- Python实现示例截图:
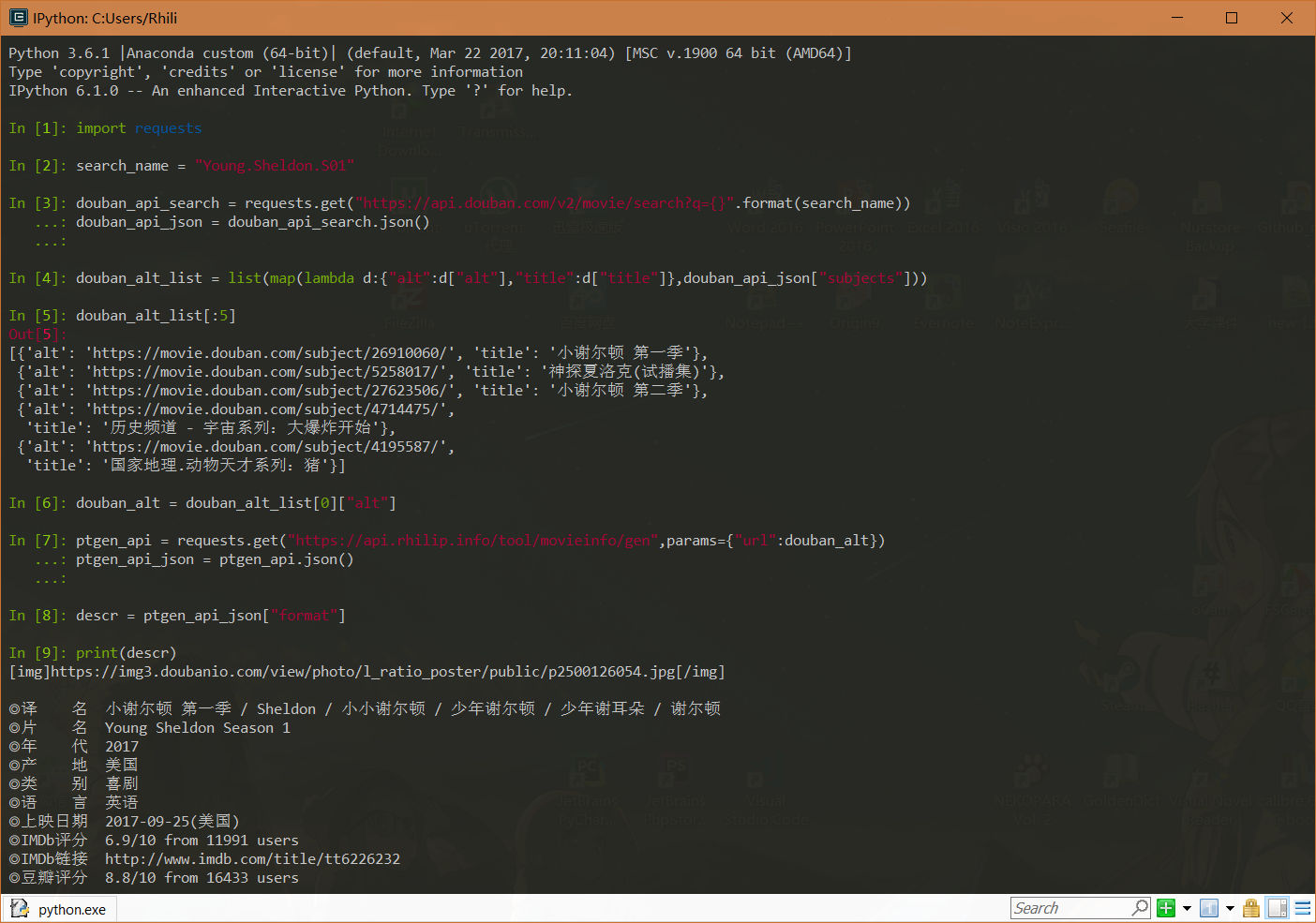
- 参考代码:
1 | import requests |
- 根据种子的hash值从mikanani.me获取种子对应的Bangumi链接,然后根据Bangumi信息生成对应简介。(仅适用于动漫转化原种)
- 参考示例: BYRBT Bangumi Info
- Python实现示例截图:
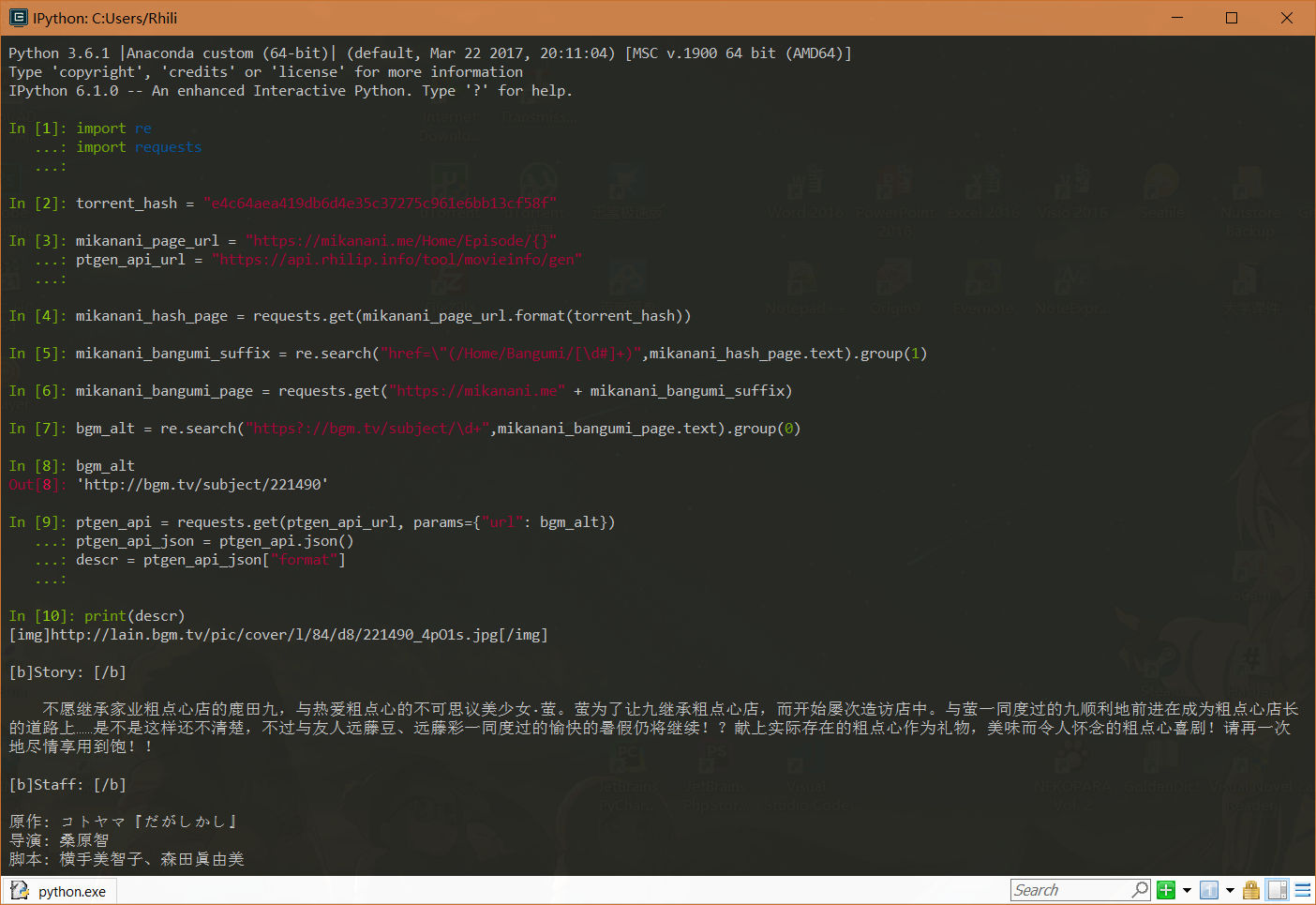
- 参考代码(此处假设对应hash及bgm链接均存在,不存在的情况请参照js实现做异常判断):
1 | import re |
发种更新简介
老种子的简介并不一定能完全使用,特别是使用自引用的方式获得简介。需要进行一些处理,删除原种子的Mediainfo信息、提示信息等,并更新原有的季度信息。
各站的处理机制均不相同,比如本人已经的实现中,BYRBT等分割原有标题信息,并在新字典中对该信息进行更新即可;而NPUPT等可能需要使用re.sub()或str.replace()等进行替换。又比如说HUDBT等站点对种子主标题有要求,不需要”.”来分割等。应因地适宜滴配置相关处理流程。
所以本处就介绍些通用的方法~~ (偷懒
- 获取Mediainfo
- 现有实现: Rhilip/Pt-Autoseed/utils/descr/mediainfo.py
- 实现机制:直接调用mediainfo软件并输出信息。
- 示例代码:
1 | import os |
- 获取单帧截图
- 现有实现:Rhilip/Pt-Autoseed/utils/descr/thumbnails.py
- 实现机制:使用ffmpeg对单帧进行截图
- 示例代码:
1 | import os |
- 制作视频缩略图
- 参考 wiki:How to take multiple screenshots to an image (tile, mosaic) 修改上面的的ffmpeg代码即可~
发布种子
我们这里使用Requests库模拟表单提交。
可以使用专业抓包工具如Fiddler获取发布数据包,当然Chrome等浏览器提供的开发者工具基本足够了。首先准备好一个已经在该站发布过的种子(直接下载一个),并填写好相关表单。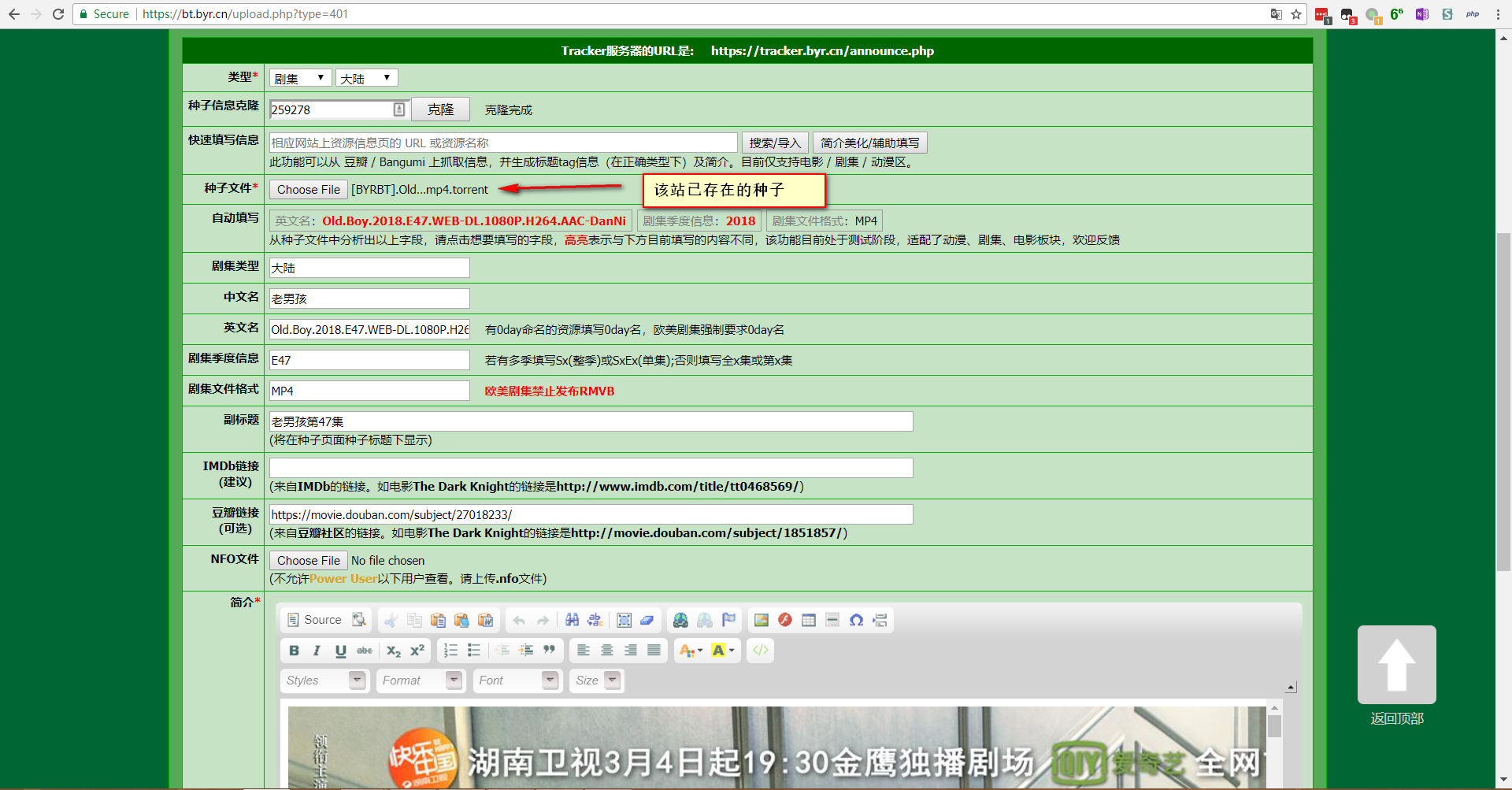
打开开发者面板,勾选Network项中的Preserve Log以防止页面跳转导致的记录丢失,然后点击发布。一般会提示上传失败。不过不用担心,实际的交互信息已经被记录了。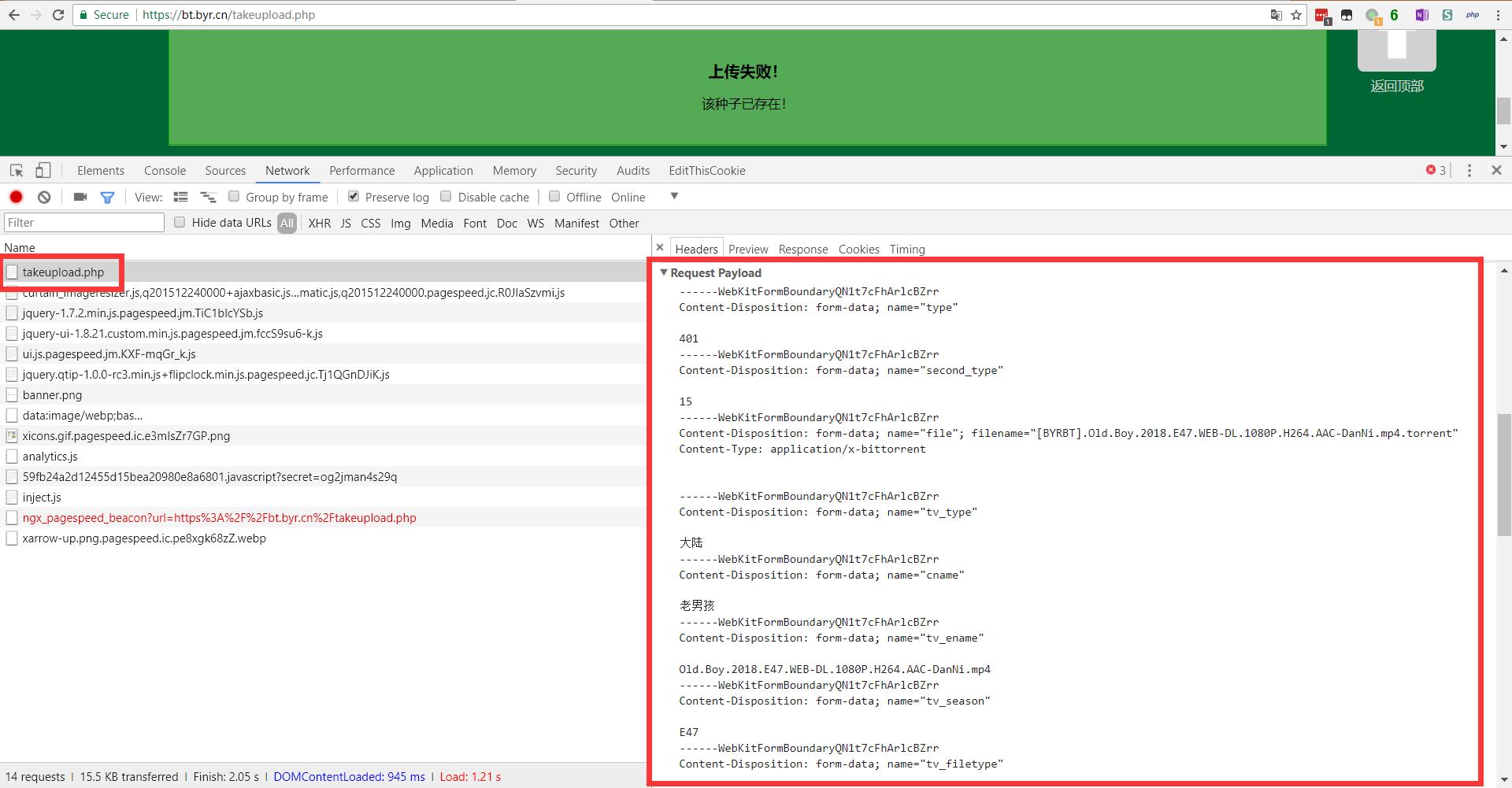
剩下的只要将这些改成Python-Requests库模拟的相关格式就行了。我这里就偷懒直接用最早的模板了。
2019.02.25注:此处代码已经无法使用,详见发种姬修复之 “请填写必填项目上传失败!”
1 |
|
一般如果发布成功的话,会做页面跳转。通过检查页面链接是否改变(跳转)或者页面提示来确定是否发布成功。
添加种子
- 设定BT软件的watch-dir,然后将发布后种子下载到该监控目录。BT软件会自动读取并添加该种子
1 | import requests |
- 通过BT软件的WEB-PRC方法(以Transmission为例)
1 | import transmissionrpc |