
前段时间(9月7日),libtorrent宣布其2.0版本开始支持 BEP 52 The BitTorrent Protocol Specification v2 的相关协议(BitTorrent v2 - libtorrent.org)。
之前我在写RidPT的时候便翻过这个定稿于2017年的标准(历史悠久),但当时并没有客户端或Tracker对该标准有实现(较长时间内可能也不会有Tracker或者下载器实现),匆匆瞄了一眼便搁置了。如今重新捡起,看看对应标准和Tracker侧如何兼容。
全文总结: Bittorrent v2并不像是为了Private Tracker设计的。其中一些诸如节省metadata体积的方法、基于文件而不是字节块的哈希方法等,在magnet、DHT等协议中或许能体现其用途,但对于PT来说,可能作用的体现并不明显。
一、Spec更改项对比
此处仅列出我比较感兴趣的几个协议更改项对比,如有需要请翻阅 The BitTorrent Protocol Specification 和 The BitTorrent Protocol Specification v2 进行更进一步的了解。
1. hash算法从SHA-1变更为SHA-256
v2协议中将哈希算法从原来SHA-1变更为SHA-256,这一改变不仅体现在了对于单一文件区块哈希中,同样还体现在了对于$->info的整体哈希中。这么变更的理由在于避免SHA-1的哈希碰撞(参见Announcing the first SHA1 collision)。这与git不同,git同样使用SHA-1作为哈希算法,但是commit的SHA-1值分布在不同仓库中,能很大程度上避免SHA-1值被碰撞。而bittorrent的相关种子infohash值是全网空间的,特别在magnet协议中,是以 magnet:?xt=urn:btih:<sha1-info-hash>的形式进行构造的,所以在全网空间中,是可能存在哈希碰撞的情况。
然而SHA-256的结果是32字节,这与目前SHA-1的20字节不相同。这就意味着如果要向下兼容的话,需要将已有的32字节SHA-256截断成20字节。目前在libtorrent中的实现便是通过扩展escape_string方法,并将最后的info_hash截断成20字节。
1 | // from https://github.com/arvidn/libtorrent/blob/ebe82ae569c23eb4fcd435e5c94e4763d4c8d4e1/src/http_tracker_connection.cpp#L110 |
2. 对文件列表结构进行重构(变成文件树形式)
这个是我个人比较喜欢的一点改变,因为从文件列表转化为文件树,能大大减少原$->info->files[i]->path 过长以及重复信息过多的问题(但这并不一定意味着种子文件大小能够减少)。
在v1中,$->info-> files 的列表可能如下:
1 | 'files': [ |
这在文件数量特别多,或者文件目录嵌套过深时,特别容易造成最终打包出来的种子大小过大。(因为冗余信息过多)。而在v2标准中,将其改为使用文件树形式,并使用$->info->file tree存放。在file tree字典内,使用一个字典空键值表示最终文件,并为每个文件提供一个哈希检验值(额外的哈希检验值在某种程度上膨胀了种子体积)。
1 | 'file tree': { |
而pieces root的计算方法为merkle hash trees,这也使得v2的种子在文件层次上是对齐的。其原理示例图如下:
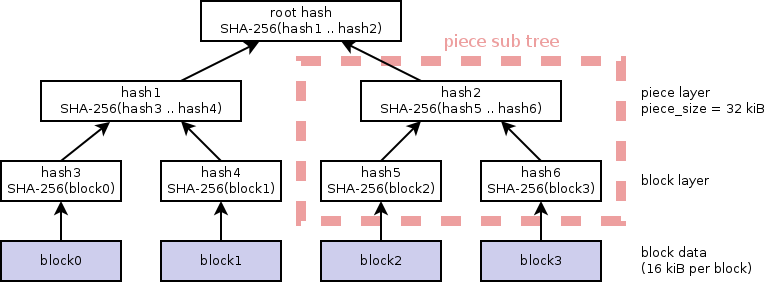
此外,对于原v1的$->info->pieces项,v2种子中也不再提供,而是将其放置在$->piece layers中,与最终的infohash值脱钩。
piece layers项在v2种子中是必须存在的。单文件大小小于区块大小的文件可以不列入该字典中,故其可以为空字典。而其键为之前在文件pieces root项出现的值,而其值为该文件每一个piece length大小的区块拼接形成,在实质上与之前的$->info->pieces项相同。
值得注意的是 piece layers项的值只考虑有效区块(不考虑对齐区块),其原文如下:
1 | Layer hashes which exclusively cover data beyond the end of file, i.e. are only needed to balance the tree, are omitted. |
3. 对Bencode方法规定的补充
在v2中对原Bencode编解码相关规则进行了补充,主要是对于utf8的支持。原文如下:
1 | Note that in the context of bencoding strings including dictionary keys are arbitrary byte sequences (uint8_t[]). |
二、种子制作测试
分别使用官网提供的工具bep_0052_torrent_creator.py以及Qbittorrent的使用同一区块大小(64kb)进行制种,观察种子结构,对比如下
多文件(文件夹)制种种子结构
一个典型的v1、v2-only、v2-compatibility 多文件种子结构分别如下(JSON格式):
1 | // v1 torrent |
单文件制种种子结构
而一个典型的v1、v2-only、v2-compatibility 单文件种子结构分别如下(JSON格式):
1 | // v1 torrent |
不同区块大小的v2-compatibility种子结构
分别使用64 KiB(65535 bytes)和4 MiB(4194304 bytes)对同一个小文件(135857 bytes/132 KB)进行测试,比较种子结构,分别如下:
1 | // piece length 65536 |
可以看出其文件的 pieces root 项的值并没有随着做种区块大小的变动而改变。(这个功能优化或将给基于infohash以及文件大小名称的辅种方法提供新的思路)
此外,由于区块大小大于文件总大小,在4 MiB区块的种子中,其piece layers 项为空字典。这也满足协议相关定义(For each file in the file tree that is larger than the piece size it contains one string value.)
同一文件夹制种测试
使用同一区块大小(64 KiB)对某一文件夹进行制种,其大小和infohash对比如下:

1 | v1.torrent |
很出乎我个人的主观感觉,在目录嵌套不深或者没有较长目录的情况下,使用v2体积做出来的种子体积与v1版种子相比并没有明显优势,反而因为对每个文件都构建了pieces root,以及额外的piece layers项,导致其体积远比v1大。
即使增大区块大小(4 MiB),由于文件夹深度及层级并没有变化,而且种子文件数量并没有达到引起质变的程度。其对比同样不太明显:

1 | multi-v1-4194304.torrent |
三、目前阶段Tracker支持方法
对info_hash取值:
由于v2的种子在汇报时,其
&info_hash=请求字段仍然为20bytes,而在BEP52规范以及libtorrent的实现中,对于汇报的info_hash取值方法是: 种子为v2的优先裁剪sha256到前20 bytes,如果还是v1的种子,则按照原来的方法实现,其代码如下:1
2
3
4
5
6
7
8// from https://github.com/arvidn/libtorrent/blob/867cf863f21747f2df7290df81a8d6a57a4d0992/include/libtorrent/info_hash.hpp#L105-L110
// returns the v2 (truncated) info-hash, if there is one, otherwise
// returns the v1 info-hash
sha1_hash get_best() const
{
return has_v2() ? get(protocol_version::V2) : v1;
}所以Tracker在接受到一个种子(被上传)的时候应该首先判断一个种子是否是v2的种子,如果是,则计算
sha256($->info),并存储前20bytes到数据库。如果不是,则计算sha1($->info)。对种子合法性的检查以及种子总大小、文件列表的获取
在Rhilip/NexusPHP的实现中,我们对v1种子的合法性检查步骤如下 Rhilip/NexusPHP/takeupload.php#L138-L184 ,这在v1中或许足够。但我们还需要对其进行更多的检验,分别为:
(强制)
meta version项存在且为2。(作为我们判断种子类型的关键依据)(强制)
piece layers项、files tree必须存在。(可选)文件length值大于pieces length值对应的文件,其pieces root值在piece layers中存在。
(不必要)Bencode的相关格式(特别是字典序),因为目前Bencode库基本都具有对其进行排序等功能,而用户上传再下载的过程,必然同时涉及到编解码,所以即使用户上传的种子并没有完全按照字典序,在Tracker计算info_hash以及重新下载时也会重新排序。而其他的,如
i004e等问题应该在Bencode库中进行解决。
除了对种子合法性检验之外,我们还需要对种子总文件体积以及文件列表进行获取。最终形成的伪代码(未经过验证)如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65$dict = Bencode::load($torrent_file_path);
$info = checkTorrentDict($dict, 'info');
$plen = checkTorrentDict($info, 'piece length', 'integer'); // Only Check without use
$dname = checkTorrentDict($info, 'name', 'string');
$filelist = array();
// 对于种子是单文件还是多文件的仍然沿用原来的方法
$totallen = $info['length'];
if (isset($totallen)) {
$filelist[] = array($dname, $totallen);
$type = "single";
} else {
$type = "multi";
}
$torrent_v2 = false;
if ($info['meta version'] === 2) {
$torrent_v2 = true;
// !!! IMPORTANT !!! 以下对于v2种子的检查仅代表本人思路,可能出现SyntaxError或者其他任何可能的意外或者错误。
$ftree = checkTorrentDict($info, 'file tree', 'array');
$piece_layers = checkTorrentDict($dict, 'piece layers');
function loop_check_ftree($d, &$totallen = 0, &$path = []) {
if (isset($d[''])) { // 到子叶了
$fn = $d['']; // 获取子叶元素
$ll = checkTorrentDict($fn, 'length', 'integer');
$pieces_root = checkTorrentDict($fn, 'pieces root', 'string');
if (strlen($pieces) != 32) {
bark($lang_takeupload['std_invalid_pieces']);
}
// 检查过长文件的pieces root信息是否在 piece layers 中存在
if ($ll > $plen) {
if (!array_key_exist($pieces_root, $piece_layers)) {
bark('long pieces not exist in piece layers');
}
}
$totallen += $ll;
$filelist[] = array(implode("/", $path), $ll); // FIXME 这样是不合适的,但是鉴于v1是这么处理的,这里沿用。事实上v2的种子本身就是树结构的。
} else {
$parent_path = $path; // 暂存一下当前的路径,方便后续恢复
foreach($d as $k => $v) { // 遍历子叶
array_push($path, $k); // 将当前项名称存入路径
loop_check_ftree($v, $totallen, $path); // 回调检查
$path = $parent_path; // 恢复路径
}
}
}
loop_check_ftree($ftree, $totallen, [$dname]); // 从根开始检查
} else {
// 按照v1的方法检查并构建相关信息
}
$filetree = filelistTofiletree($filelist);
// 计算infohash
if ($torrent_v2) {
$raw_infohash = hash('sha256', Bencode::encode($dict['info']));
$infohash = substr($raw_infohash, 0, 20)
} else {
$infohash = sha1(Bencode::encode($dict['info']));
}
四、其他/总结
Tracker并没有能力主动将种子从v1升级到v2版本,而同时维护支持v1和v2的方法又额外加重了Tracker的负担。此外,Bittorrent v2将区块hash放在info外,在info内仅保留文件根hash的操作(用来节约metadata),并不适合使用种子文件分化的PT站点。
客户端制作向前兼容(backwards compatible)的种子得不偿失(因为对同一个区块要同时进行sha1和sha256),而只制作v2支持的种子在目前(2020年9月)没有Tracker或者btclient能识别。
不可否认,随着libtorrent v2的正式释出,基于libtorrent的Deluge和qBittorrent将会可见地对bittorrent v2 进行支持。 (e.g. qBittorrent https://github.com/qbittorrent/qBittorrent/pulls?q=libtorrent+2.0 ) (但这可能并不能改变国内PT站点uTorrent横行的现状,此外Transmission 很早之前就有仍提出对bittorrent v2的支持,但目前最新的Tr 3并没有相关反映)
对于同一个文件,不管做种区块如何选择,其pieces root始终相同,对于v2的种子,做种区块只能影响piece layers的情况。这或许能为自动化辅种软件提供新的思路。
对于站点维护者来说,可以等等此feature相关实现,再考虑是否并入站点代码中。