
此工具已不维护,请转用 ronggang/PT-Plugins-Plus
工具介绍
基于TamperMonkey插件提供的GM_xmlhttpRequest方法,模拟本地用户请求,获取对应站点搜索结果,整理并在单页面中显示。并可依据搜索结果的发布日期、大小、做种人数、下载人数、完成数信息进行排序。
你无需像其他软件一样复制以及维护你的Cookies及登陆信息,也不需要考虑二次验证或者安全问题。打开浏览器,安装脚本就能使用。(这句话真像搞传销的)
本人暂时无支持国外PT站点搜索的计划,如果你有类似需求请使用该脚本:BT MetaSearch 作为替代。
页面: https://rhilip.github.io/PT-help/ptsearch
配套用户脚本: ptsearch.user.js
百度贴吧介绍页面:2018新年礼包:“Pt-Search”【pt吧】_百度贴吧
Issue反馈页面:Pt-search 反馈页面
搜索展示
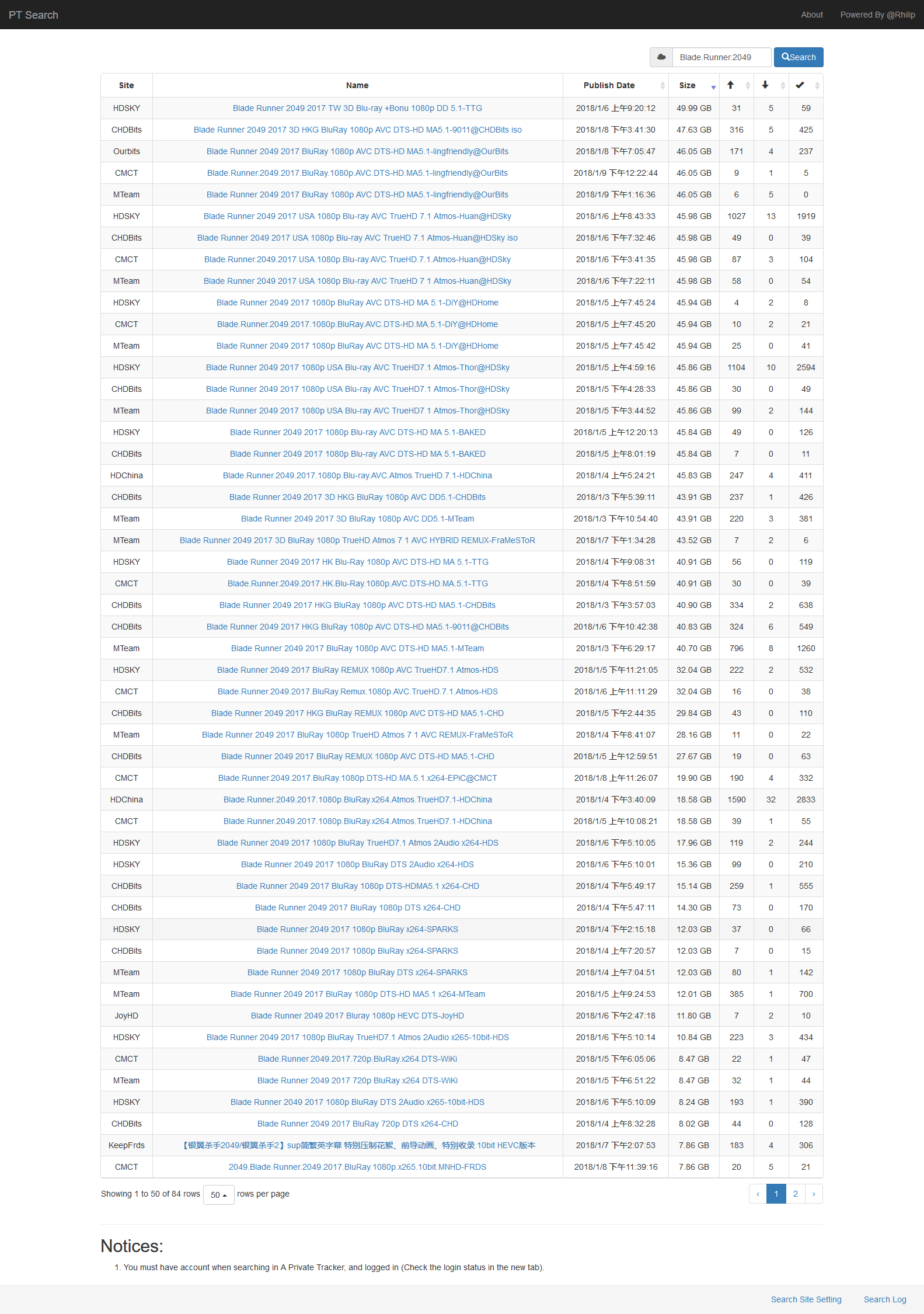
使用说明
不想写(或见贴吧介绍页22楼他人“详细”使用介绍~)
- 安装 TamperMonkey 以及脚本文件(在未安装的情况下页面会提示安装)
- 页面右下角设置中配置搜索站点
- 输入关键词并点击搜索按钮(如果你不输入任何关键词的话,会默认读取种子列表页第一页全部种子)
二次开发
总要求
- 二次开发请在fork的基础上修改,并望能在测试无误情况下提交commit及pr。
- 禁止汉化展示页面
ptsearch.html,禁止修改右上角版权信息及捐赠信息。
新增站点
你需要有一定的Javascript、jQuery、Bootstrap、Bootstrap Table的基础或阅读对应文档的能力。
在
/json/site.json对应项中添加站点信息,其中,jyw列表存放教育网站点、gw列表存放国内公网站点、wz列表存放外网站点、bt列表存放BT站点。如果某个站点你想添加但不想启用,请放在disable列表中。编辑
ptsearch.user.js用户脚本。在脚本开头添加此条已不需要,目前脚本使用connect字段允许脚本使用GM_xmlhttpRequests方法连接站点,如// @connect bt.byr.cn// @connect *来默认请求所有可能站点,但此条依据插件设置,需要用户在向目标站点请求时同意相关请求或直接点击允许该脚本全部网络请求。在脚本
// 自定义站点请添加到此处注释之后或其他合适位置添加对应站点解析方法。你需要从站点的种子列表中获取站点简写(site)、种子名称(name)、种子链接(link)、发布日期(pubdate,以unix timestamp形式)、种子大小(size,以bytes计)、做种人数(seeders)、下载人数(leechers)、完成人数(completed)信息。并构造字典使用BootstrapTable的原生方法table.bootstrapTable('append',param)更新表格(向表格添加新行),但更建议使用包装好的table_append(dict)方法,允许在插入表格信息的同时,将数据打log(依据用户设置)。你可以使用
writelog(string)方法在合适的解析位置打log。请注意,使用CSS选择器定位DOM元素时,因注意因为用户等级(普通用户或管理组)或者设置(时间设置等)的原因,不同用户在搜索页面的dom结构可能有所不同(注意,此处指的是不受其他用户脚本影响的干净页面)。应尽可能使用class属性来定位元素或filter方法来定位元素,仅在无法实现以上定位方法时才使用children、parent、siblings、next、prev等方法。(注意,你不一并必须得使用jQuery进行操作,任何可以正确的定位信息的JS原生方法均可使用。)
请注意,在配置通用脚本时,应注意
时间显示类型此选项会影响NexusPHP种子列表的DOM结构,如果错误,会导致时间结果显示为Invalid Date。一个典型的基础方法
Get_Search_Page已经被定义,你应该使用该方法来获取搜索页面,而不是从GM_xmlhttpRequest开始,除非该方法不能满足你的需求。
1 | function Get_Search_Page(site, search_prefix, parser_func) { |
Get_Search_Page这个方法接收以下三个参数:
| 参数 | 意义 |
|---|---|
| site | 站点名称,用来检查用户是否启用 |
| search_prefix | 搜索链接前缀。脚本会自动在此后补加搜索关键词 |
| parser_func | 回调函数,用于解析对应页面并生成搜索信息交给bootstrapTable |
从上面示例代码从可以看出,你可以看到,parser_func依次提供了4个结果,其中res是原始xmlhttpRequest对象,你可以在GM.xmlHttpRequest - GreaseSpot Wiki的Response Object中了解该对象的具体信息,doc是原始的网页代码,body是从原始网页代码提取<body>中的信息,而page则是一个经过jQuery解析的body对象。关于解析搜索页的具体写法,你可以参照已有的其他解析方法来书写。
- 以下为一个经典的NexusPHP框架的PT站点解析方法(某一版),此方法已被定义为
function NexusPHP(site, url_prefix, search_prefix, torrent_table_selector),对于魔改程度不大的NexusPHP站点你可以直接调用。
1 | function NexusPHP(site, search_prefix, torrent_table_selector) { |
- 所有的自定义解析模板应被定义为
Site(site:str,search_prefix:str,?)方法,从而允许后期扩展以及调用。不建议将具体脚本调用方法以及方法定义混杂放置。
常见问题
Issue反馈页面上还有部分请移步阅读。
- Q: 时间结果显示为
Invalid Date? - A: 本人主要在时间显示类型为
发生时间下进行脚本开发,仅对类型设置为已去时间(默认情况)进行了适配,如果存在问题,请在控制面板-网站设定-时间显示类型将其类型设置为发生时间。此外,部分站点设置请保持站点默认设置。

对以下站点强制要求修改时间类型为发生时间:葡萄(SJTU)
- Q: 一个站为什么只读取搜索结果中前50(100)个结果?
- A: 本脚本只读取搜索结果的第一页并解析,关于站点默认显示的单页种子数,请在
控制面板-网站设定-种子页面-每页种子数中调整。如果已有结果仍不能搜索到合适结果(如在第二页等情况),请注意调整搜索关键词或跟在站点种子数设置。
- Q: 为什么搜索结果中有条目信息不在我提供的关键词范围中?
- A: 本工具直接调用目标站点的搜索功能,与你在对应站点使用相同关键词搜索结果相同。但只提取了主标题信息进行展示,可能存在关键词在副标题、正文中的情况。如果排除以上情况仍有误,建议咨询对应站点(比如使用了非SQL搜索的NPUPT)。
- Q: 为什么不加站点全部勾选或者全部反选?为什么默认勾选的是
BYR?为什么有的站点不能勾选? - A: 不想加,本人喜欢,就这样,请自己在右下角站点设置种勾选已启用的站点。此外,勾选全部站点会导致点击搜索瞬间卡住浏览器,所以你应该选择自己需要的站点进行搜索。不能勾选的站点是因为已有适配计划,但未完成站点解析工作,请等待脚本更新。
- Q: 为什么不没有XXX站点搜索?
- A: 没号。如果需要我添加请在确认不违反网站规则的情况下 携带网址、账号、密码、一定金额的红包 来告知本人。如果你具有一定Javascript基础,欢迎依据上文
二次开发文档,对本脚本进行扩充。本人欢迎任何测试过能正常使用的pr。
- Q: 为什么在Developer tools的Console面板中有这么多错误提示?
- A:
脚本使用JQuery解析请求返回页面,在解析过程中会请求部分图片资源,但是多数站点对应资源都是用的是相对地址,这在脚本页面是不存在的,故返回了大量404错误,但这不影响脚本解析。你应该寻找非404错误。已更改解析方法,目前应该不会出现此问题。
- Q: 怎么进行问题反馈?
- A: 本人不接受使用方法咨询(这个脚本已经很傻瓜了,别让我瞧不起你),如果你确定该问题的产生原因是因为用户自解析脚本的原因。请在Github上对应repo上开issue并注明Log。
开发日志
- 2018.01.07 确定思路可行,完成前端展示页面及配套脚本的初步开发
- 2018.01.08 完成脚本开发,填充第一批站点(可以直接使用NexusPHP解析模板套用的站点)
- 2018.01.13 修复上版(v20180111)中的一个错误,完善NexusPHP解析模板,完成第二批站点填充。脚本进入长期稳定支持期。
- 2018.01.30 添加站点
HDStreet(原蚂蚁类模板)的支持,但因目前就发现此站点使用该模板,暂时未定义成块方法。修改脚本解析方法,为先使用原生DOMParser()解析原始文本后获取<body>元素再使用jQuery继续解析。 - 2018.03.26 修改NexusPHP原有解析方法中时间dom解析的方法,使之适配除葡萄(SJTU)以外的所有NexusPHP系站点;修改所有解析方法为块方法。
- 2018.03.31 增加CCFBits站点