在别人的怂恿下写了个这样的工具。原来的想法是在这里就可以直接查看各站最新的种子,方便多站辅种,后来想了想扩充了下,用爬虫补抓了国内各站的历史种子信息,就做成了现在这幅样子。
已关闭!
本工具不是跨站点搜索,你应该使用Pt-Search作为聚合搜索工具!!!!!
禁止滥用!禁止高强度连续请求!
本工具禁止在任何论坛、贴吧、Pt站点、QQ群等公开场所宣传。
本工具尊重站点要求,如站点禁止抓取展示,请及时告知。
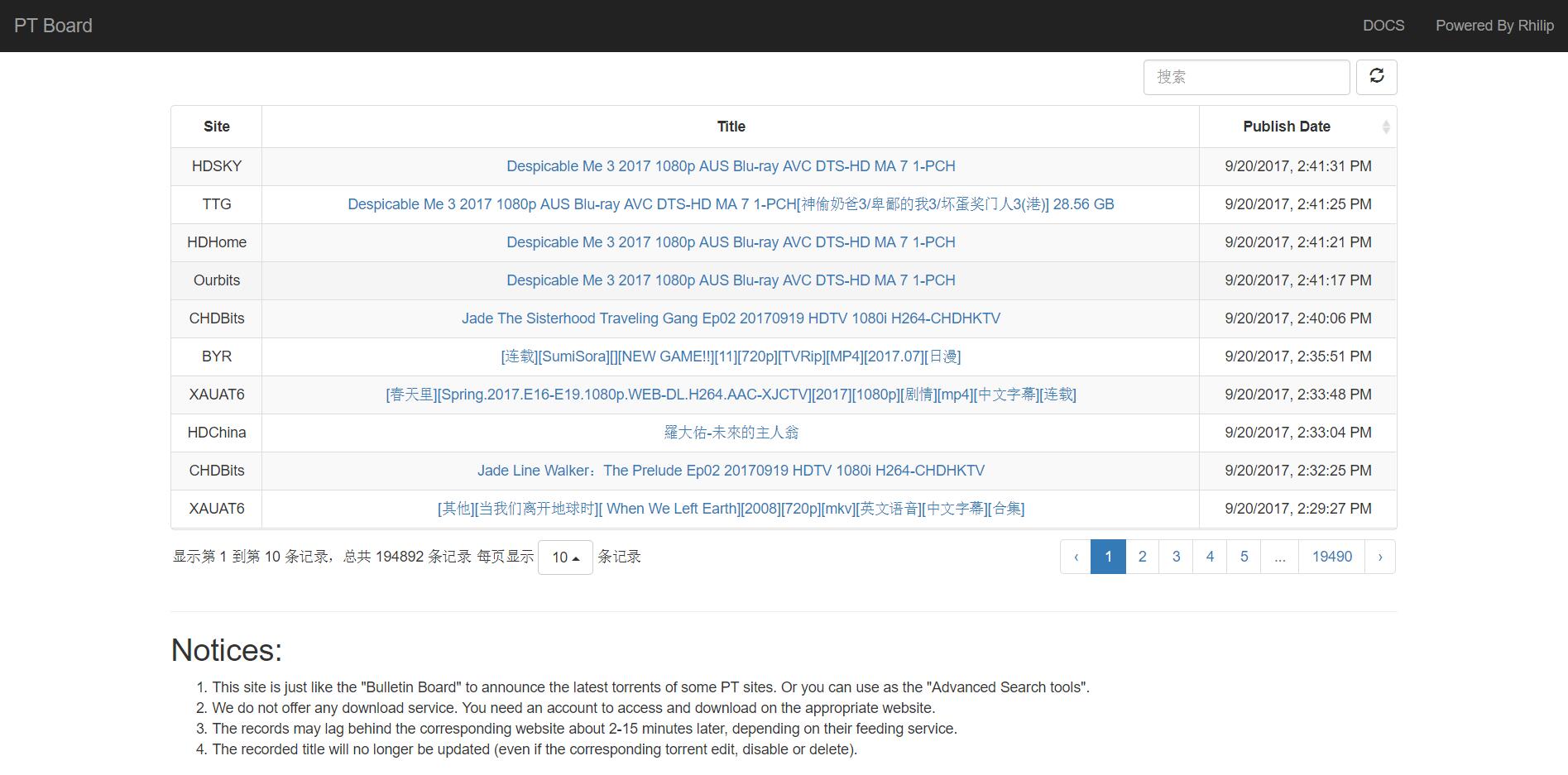
因为前后端是分离的,前端是静态页面,所以就用GitHub Pages来存储了,就不单独放在自己的页面中了(而且直接push就可以修改页面很方便欸有没有,其实自己也有备份)。相应的源代码在相应的repo中,可以自己修改(如果觉得我写的前端不好看(用)的话)。
Official DEMO URL:
非上面两个地址的展示DEMO地址均为他人第三方修改,不保证可用。
Docs: ptboard/README.md
与某站供up以上才可以使用的高级搜索不同,他们的是需要搜索时才在各站进行搜索,并抓取结果(中间可能因为站点无反应、Cookies认证过期或者站点变更结构等原因而不能使用)并返回。而这个是读取各站的RSS源,获取最新的种子后,存入库中,搜索时直接查数据库。
缺点在于,在脚本抓取有效期后不会对种子的情况(更改简介、被禁止、被删除情况进行改正)进行更新。(具体见2018.03.18更新说明)
更新频率
- 目前从RSS抓取的间隔为3分钟(以保证及时),但是由于各站RSS的更新情况,可能会有2-15分钟的延迟吧。(毕竟不是irc这种实时的)
- 自建的伪RSS(即分析站点种子首页获取最新种子信息)抓取间隔为30分钟(因为这些站没必要那么频繁的获取)。
- 部分不能使用通用模板抓取解析的站点时间一般在1-3小时或更长时间。
- 六维空间(6V),什么时候想起来什么时候更新~(如果你有稳定的教育网服务器请联系233333
- 从PreDB Live抓取间隔为5分钟(在限制订阅条件后同样没必要特别频繁抓取信息)。目前订阅类别为见下,主要拿来做国内站与美剧Scene发布时间对比,如果有其他要求,我再修改~
- group: SVA|AVS|KILLERS|DIMENSION|FLEET|W4F
- type: TV-XVID|TV-X264
更新日志
- 2017.09.18 完成后端RSS抓取解析部分,及API部分
- 2017.09.19 回溯抓取WHU、NYPT、AirPT站点所有种子数据完成
- 2017.09.20 赶在今天结束之前,爬虫终于把麦田(MTPT、NWSUAF6)给爬完了
- 2017.09.21 完成了BYR、XAUAT6、SJTU、Hyperay的回溯抓取,并移除了之前回溯过程中在BYR、WHU、NYPT重复抓取的数据(其他站未见重复抓取数据)
- 2017.09.22 历时2天,爬完知行约28W条种子数据(他们站中发布时间只精确到分钟,秒统一用00替代。);完成HDChina、NPUPT、HDTime、HDU、JoyHD(67763之前)、CUGB、CHDBits、TTHD的回溯爬取(未排重)
- 2017.09.23 发现昨天反爬TTHD的时候,站点信息填成了OpenCD,已修正
(我一定是看书看糊涂了)。完成了CMCT、HDSky、Ourbits的回溯爬取。完成hudbt在136435之前的种子信息爬取。 - 2017.09.25 爬完MT的普通区种子。
- 2017.09.26 完成u2的回溯爬取。添加HUDBT的伪RSS更新。
- 2017.09.27 爬完MT的隐藏区(都懂。。。)种子信息。添加HDCity的伪RSS更新。完成TCCF的回溯爬取。
- 2017.09.28 爬完HDCity、OpenCD种子信息。
- 2017.10.05 修改TTG的RSS链接(补充游戏区),回溯补抓TTG
影视&音乐及游戏&软件资源。修改RSS脚本,并添加IPT(自2499360起)、港知堂(GZTown,自3690起)、FL(自522973起)的RSS订阅。 - 2017.10.06 移除IPT和FL两个国外站(刷屏太恐怖了,还是弄国内的好了),更改为从PreDB中更新;添加Antsoul(都快闭站了,就做个备份纪念吧2333)的RSS订阅,并完成回溯;完成GZTown的回溯抓取。添加JoyHD的伪RSS更新。添加CCFBits的RSS订阅。修改默认前端不提供分页功能,API不变。
- 2017.10.07 补KeepFrds的回溯抓取,并完成。修RSS脚本中一个CCFBits中时间转换为UTC的时间戳错误问题。完成CCFBits的回溯抓取。
- 2017.10.08 更新了下后端返回total值的方法,加快在搜索条件下的响应。具体为
无搜索值时,返回总行数的粗略值;有搜索值时,如果搜索结果行数小于limit参数,则返回具体行数,否则返回limit值(原来要COUNT所有符合搜索条件的记录,随着表越来越大,严重影响了响应)。修改后端分词的机制。补加HD4FANS的RSS订阅。 - 2017.10.09 补HD4Fans的回溯抓取。
- 2017.10.10
因为被挂v2ex,补加token认证。给每个由ProjectPoi生成的token一周的生存期以及25个搜索次数。(该数值可能会不经通知的改变)(Update: 2018.01.01 暂时移除token认证机制) - 2017.10.11 增加后端API的更多筛选项:
start_time,end_time,site,no_site。前端不做适配。 - 2017.11.1 收录六维空间(6V)帖子编号
1604910(2017-11-1 22:12) 之前的所有种子贴(非水区、图区等论坛贴)。因该站不支持非教育网IPv6地址访问,所以之后的更新采取手动更新的方式。 - 2017.11.16 补加国内VPS备机抓取。(由此可能会造成部分种子被重复抓取,不过会被定时脚本给清除)
- 2017.11.18 修正6v更新爬虫,补加候选区爬取和重爬机制。
- 2017.12.15 给数据库
title字段加全文索引,加快搜索速度。 - 2017.12.17
跟着(可能并没有正确的从数据库中删除所有被删除的种子信息OrzNPUBits站点3万大删种行动的脚步,移除在此次行动中被删除的所有种子记录(约 31k 行)。 - 2018.01.01 更改后端数据库存储引擎为MyISAM加快搜索速度,修改total返回值为实际行数。因ppoi认证不稳定移除token认证。移除备机抓取。API进入长期稳定期。
- 2018.01.14 修改表结构,添加
UNIQUE KEY,相关DDL:ALTER TABLE `ptboard_record` ADD UNIQUE KEY `unique_sid_in_one_site` (`sid`,`site`),使得不会出现单站点重复种问题。 - 2018.01.31 部分站点存在offer区种子在通过候选后直接进入种子区的情况(这一现象不能被之前脚本正确处理,目前发现U2、HDChina、HDHome、MTeam可能存在该问题),出现该问题的站点会在稍后补抓可能在平时抓取中遗留的信息,并已经修改后端抓取脚本处理该一现象。
- 2018.03.10 修改后端数据库,移除原
ptboard_record的link字段,改为由查询时与统计表信息拼接形成。节省了约100M的磁盘空间(200万行,含数据与索引)同时修改后端API,不再返回uid这一主键。 - 2018.03.18 增加DUTPT(大工PT江湖)的历史数据(因一直没关注,脚本中途暂停,直到03.20才正式完成)以及抓取,暂定抓取间隔为1小时;修改后端RSS和伪RSS脚本插入语句为
INSERT INTO .... VALUE(.....) ON DUPLICATE KEY UPDATE .....,使得在脚本抓取有效期内(视该站种子更新频率,一般在发布后2-3小时甚至更长时间内)种子主标题信息能随up主编辑更改,过后不管。 - 2018.03.22 更新DOCS帮助文档;修改后端API处理,对
site和no_site字段进行取值限制防止可能的注入,对search字段进行限制,分词后小于1个字段的将被排除,减少对数据库搜索的压力。 - 2018.08.10 Bye
Bye老子没空陪你们玩了,关闭后台了。 - 2018.10.09 增加
百川PT,缩写直接域名ghtt吧 - 2018.11.08 添加
HDArea以及部分新开小站 - 2019.01.07 补充 教育网站点——清影
HIT - 2019.02.17 修改数据库表结构
- 2019.06.08 修正一些站点的订阅信息(包括链接、站点名称、关闭站点取消订阅),补爬TTG(因为原订阅链接失效导致的漏种)以及修复订阅时间错误漏洞
未来想法
- 对已有存库资源进行复查。移除站点已删除种子信息,修改部分更名了的种子信息。
- 通过种子列表页遍历脚本,实现种子的定期增量更新。
添加按站点和按时间段搜索功能(这个肯定要改后端,等过段时间再看下后端api怎么改方便,会不会坑掉那)重复抓取数据清理改成单独脚本,在全部站点回溯基本完成的情况下运行(这个写好了就等运行了2333)
存在的问题
TTG的RSS源中没有提供发布时间,采用抓取时间替代(补爬修复)- 在回溯抓取时,部分站点存在将时间戳错误转换为timestamp的情况(未影响RSS源种子发布时间)
HIT的公网访问似乎有问题,VPS上ping不通,不能抓取(大清乙烷,不管了)蚂蚁PT年久失修,暂时不做抓取了(已补,在VPS上写了hosts才上去)(已关站);北洋园估计要明年初才开站,到时候再补。(已补)HDCity的RSS源和其他基于NexusPHP的站点不同,需要更换规则(使用自解析抓取替代)JoyHD站点的SSL设置存在问题,导致爬虫或者feedparser爬取时抛出SSLError问题无法抓取。-> 单独写脚本执行抓取。在无搜索值时,返回的是(更改表引擎为MyISAM解决)information_schema表中粗略的总条目数,与真正值之间有1-2k的误差(这个误差已经扩大到了w级别了)。会导致点击最后一页时,无数据返回或者点击最后一页时,还有更久远的最后一页(迷之最后一页)。(2017.10.06 修改默认前端不提供分页功能,API不变) 然而并不想改后端。