
用到的库安装方法:pip install progressbar2 requests
1 | import progressbar |
用到的库安装方法:pip install progressbar2 requests
1 | import progressbar |
前注:由于该repo的更新及重构,rtinst脚本的重大变更,此处的安装步骤已经不能使用,仅供参考。
以前发布美剧0day都是本地ut下种发种,那时候就很羡慕类似WHU或者CMCT这样自建有Autoseed的站点。趁着自己还熟悉一些编程,就询问了群里另一位开发种机的dalao怎么建发种机。然后得到了这样的结果(扑。。
好吧,那就自己写吧(其实我原来想直接借用的QAQ)。然后就用Python写了个以transmission为PT工具的,专司发布剧集的发种机。
当然本文并不是讲这些故事,主要来梳理下怎么搭建这个Byrbt-Autoseed。(这是一个很复杂的过程QAQ
来先梳理下,pt工具是transmission,因为有相关python库而且好用(然而并不是,在实际写程序以及运行过程中遇到了很多问题);RSS订阅依赖flexget和irssi-autodl, flexget一则处理国内站点rss源方便,二来能填补irssi-autodl中未能订阅成功(以及不能发布proper的情况,估计是我没设置好的原因2333),irssi-autodl就更不用说了,外站必用;数据库管理用mysql,在写程序过程中也曾想过使用本地sqlite,然而实际考虑过一些问题后发现还是mysql好用,而且可以远程控制,方便后期维护,虽然有内存占用的问题存在,但是应该注意到seedbox在多数情况下不用考虑内存问题。
本文以在Vultr新开一台全新机(演示完已删除)为背景叙述。所用系统为Ubtuntu 14.04。开有IPv6支援,全程使用sudo提权或者使用root用户。
备忘用:
参考以下文章并修改:How To Install Transmission on Ubuntu 14.04 - idroot
此脚本已于Github上维护 NTwiki - Hide the got ship.user.js
怎么办,好像又写了个很无聊的脚本。。。
看介绍就知道了。。。
(对,图鉴中没有开的还有这么多船QAQ ←对,所以我要开始打捞了
如果没有记错的话,接触到这个垃圾的游戏那段时间是Pokemon Go正火的时候,因为锁区的原因,不能玩上的我选择了Ingress作为代替,然而没想到一玩就玩了这么长时间(20160715-20170114)。
不过都结束了,可以结束每天上学前打开游戏的签到,可以结束寒暑假在家每天早上骑着自行车遛边衢城的每一个po,可以结束每天傍晚给自己成就po充电的过程(虽然成就牌已经黑了….)
嗯,我也不计较是猩猩的那个机制如此坚定地认为我是架飞机了,既然如此,我也有弃玩的权利嘛。
谨以此文纪念。
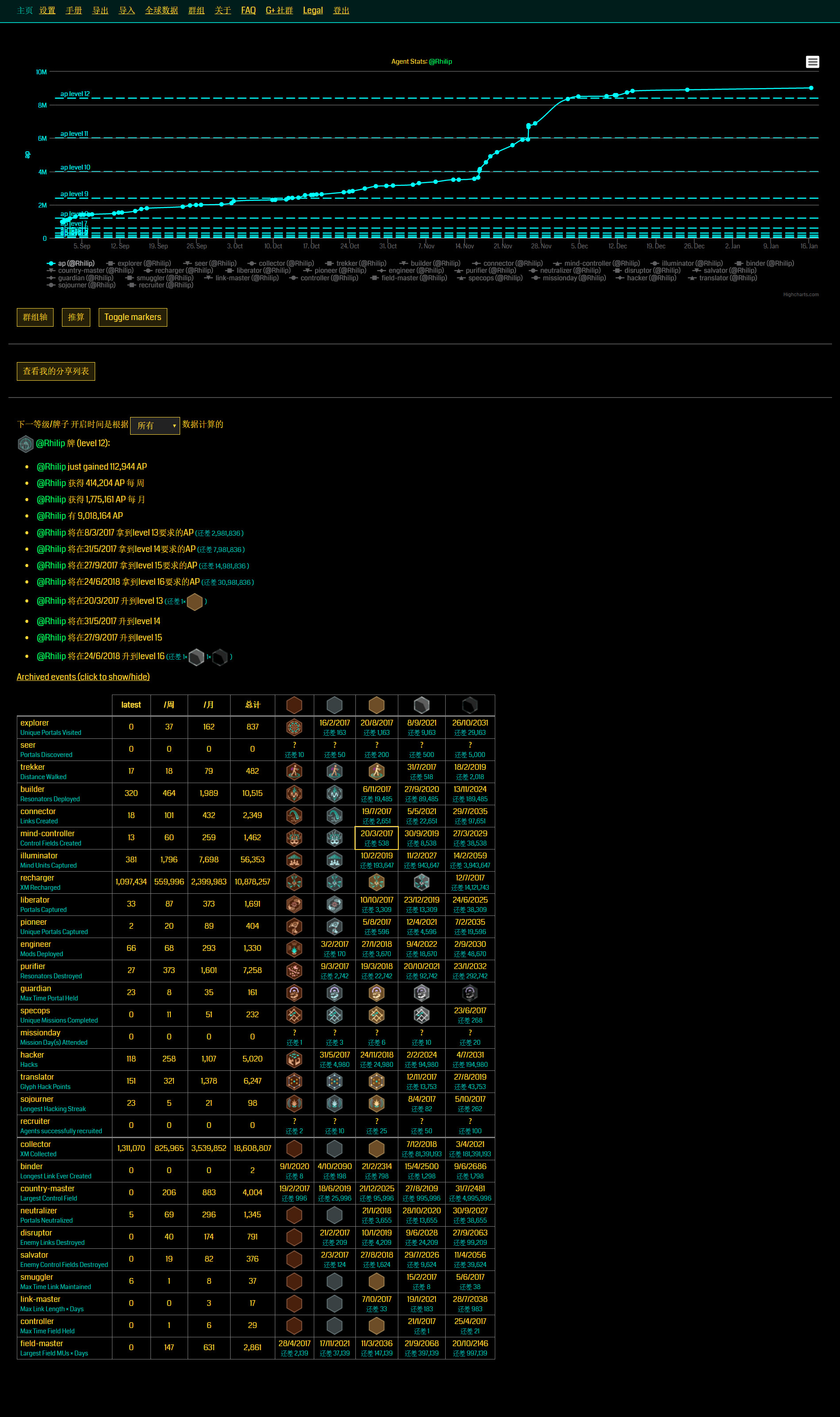

项目地址:Rhilip/icourse163-dl
这个爬虫更新到v20170116(93ea55d4d215f675b8e2fae8003e19c03ceed0ad)这个版本,也算是差不多完成了吧。今后可能就不做更新了。
最早开始抓MOOC的时候,用的是插件的方法读视频的地址,如果没有记错的话,应该是Flash Video Downloader这个插件吧。当视频链接被读到后,就能插件被嗅探出来。早期发在byrbt的MOOC课程都是使用这种方法(因为那时候是为了自己平时使用方便临时抓的),按编号来说应该都在20之前滴说。
顺带那时候还没有发布MOOC的任何计划,就连教育网PT站点是什么都不知道QAQ。。。
然后很长时间我是用F12来读视频地址的。相比早期的插件法,可以很好的防止网易的垃圾服务器长时间无响应(也不知道是学校垃圾校园网的问题还是网易的问题。。。)。F12打开Chrome的开发者工具,在Network面板中用Filter过滤出来mp4。这种方法我大概抓了20-40门课。那时候感觉这真的是一件体力活。。。。
然后我开始动手写这个专门拿来抓中国大学MOOC下载链接的脚本了。。
不过自从大一学完了C语言后,基本就没写过程序(毕竟不是计算机专业2333)。还是遇到了很多的问题。比如如何解决登陆验证(后来用Session和Cookies绕过,带来的麻烦就是每隔一段时间就要更新)、比如如何清洗dwr交互文件的信息(后来直接用re来洗了)以及如何处理下载课程文档和字幕(脚本开源在github后多数commit都是和这个有关)等。
脚本的初稿(差不多就是 611615d 这个样子)大概写了半天多吧,得益于我看文档理解运用的能力。。(一个没有用过Python来编程的孩子心里痛QAQ
可以看出来,文件还是有C的影子(哪怕现在也是2333,
另外,抓了这么多中国大学MOOC。不得不吐槽部分学校发布的课程简直不能看,命名还统一都是“课程视频”,真是呵呵了。
关于脚本,如果真要说的话,应该还没有完全完成吧。关于抓取说明和课程介绍的txt文件、课程的封面图和介绍视频等(写了一些后来弃坑了,引入bs4也就是为了这个);抓取课程的时候统一只抓视频和文档,没有对章节进行处理(见下面的示例代码),造成了后期整理课程视频时候的麻烦。待他人fork后跟进吧,或者什么时候我又提起修改代码的兴趣(16年末一堆课程完结真是抓吐了我滴说)
1 | s19.chapterId=1002140025;s19.contentId=null;s19.contentType=1;s19.gmtCreate=1476768213802;s19.gmtModified=1476768213802;s19.id=1002445198;s19.isTestChecked=false;s19.name="1-2 \u8BA1\u7B97\u673A\u786C\u4EF6\u7CFB\u7EDF";s19.position=1;s19.releaseTime=1476768600000;s19.termId=1001877005;s19.test=null;s19.testDraftStatus=0;s19.units=s28;s19.viewStatus=0; |
更多的是v20170116的脚本备份,建议访问github查看~
在某个奇葩的文件(temp.txt)中,有这么一串字符串
1 | s17.chapterId=1002037128;s17.contentId=null;s17.contentType=1;s17.gmtCreate=1471894343268;s17.gmtModified=1471894343268;s17.id=1002294678;s17.isTestChecked=false;s17.name="\u7B2C1\u8BB2-\u521D\u6B65\u8BA4\u8BC6\u6570\u636E\u5E93\u7CFB\u7EDF";s17.position=1;s17.releaseTime=1473040800000;s17.termId=1001785022;s17.test=null;s17.testDraftStatus=0;s17.units=s28;s17.viewStatus=3; |
现在用Python读入,并用re模块解析获取name中的信息
1 | import re |
然而此时输出name的话,你会发现输出是\u7B2C1\u8BB2-\u521D\u6B65\u8BA4\u8BC6\u6570\u636E\u5E93\u7CFB\u7EDF,而不是我们预先想要的该段Unicode对应出来的中文字符。
但是直接对该字符串进行decode(‘unicode_escape’)的方法时,Python 3 会报错提示str并没有decode的方法” AttributeError: ‘str’ object has no attribute ‘decode’ “。
因为 Python3 中的 str 对象实为 Unicode 统一码,而不是Python2中的字节串,并没有某一(如ASCII,GBK之类)具体编码值,没有某一具体编码值固然也就不存在decode方法来对其解码,而应先对其 encode 成某一具体编码实现再以某一编码形式去解码再交由用户处理。(thanks x1ah@Github)
故给出了以下的处理方法:
1 | name = str(re.search(r'.name="(.+)";', index).group(1)).encode('utf-8').decode('unicode_escape') |
相关知乎讨论:Python3中如何得到Unicode码对应的中文?
这是我最近动手写的唯一一个脚本QAQ
之前想好的把以前写的Byrbt MOD Help脚本拆分大改的想法(坑),到现在还没有填的打算(~~~人家太忙了啦,舰R开活动又要准备考试~~~)
因为最近Github的仓库在修改,所以这个脚本的代码公开在了Greakfork上
脚本安装地址:
安装好后会在动漫栏后面添加一个按钮“导出Bamgumi简介” (我觉得放在那里挺美观的QAQ
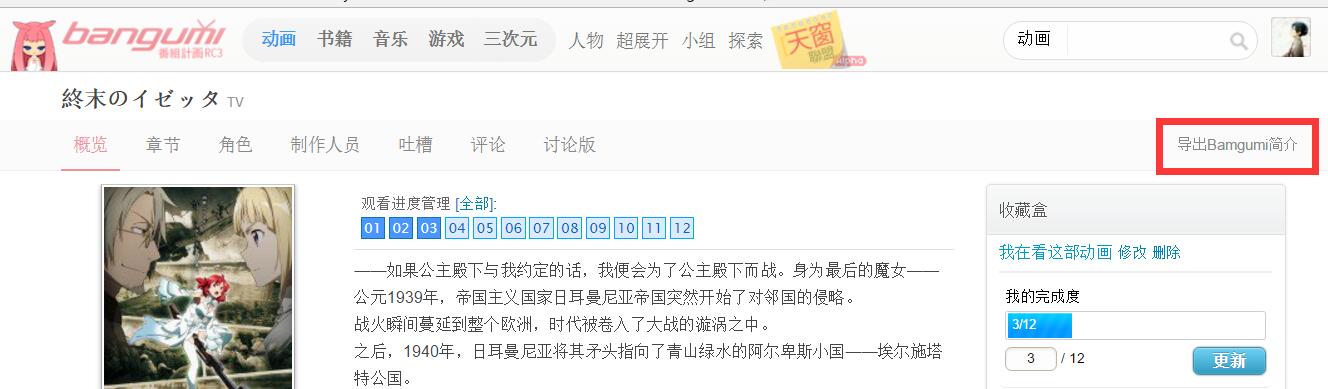
点击按钮,弹出输出文本框。(默认情况下输出BBcode格式的简介)
然后复制粘贴即可。
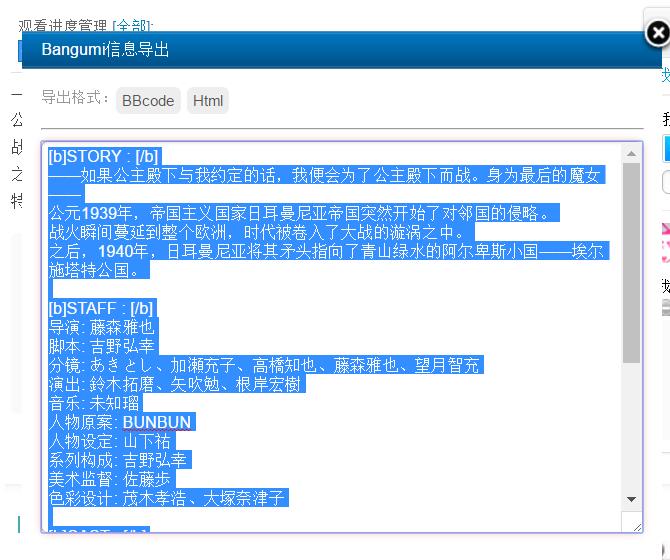
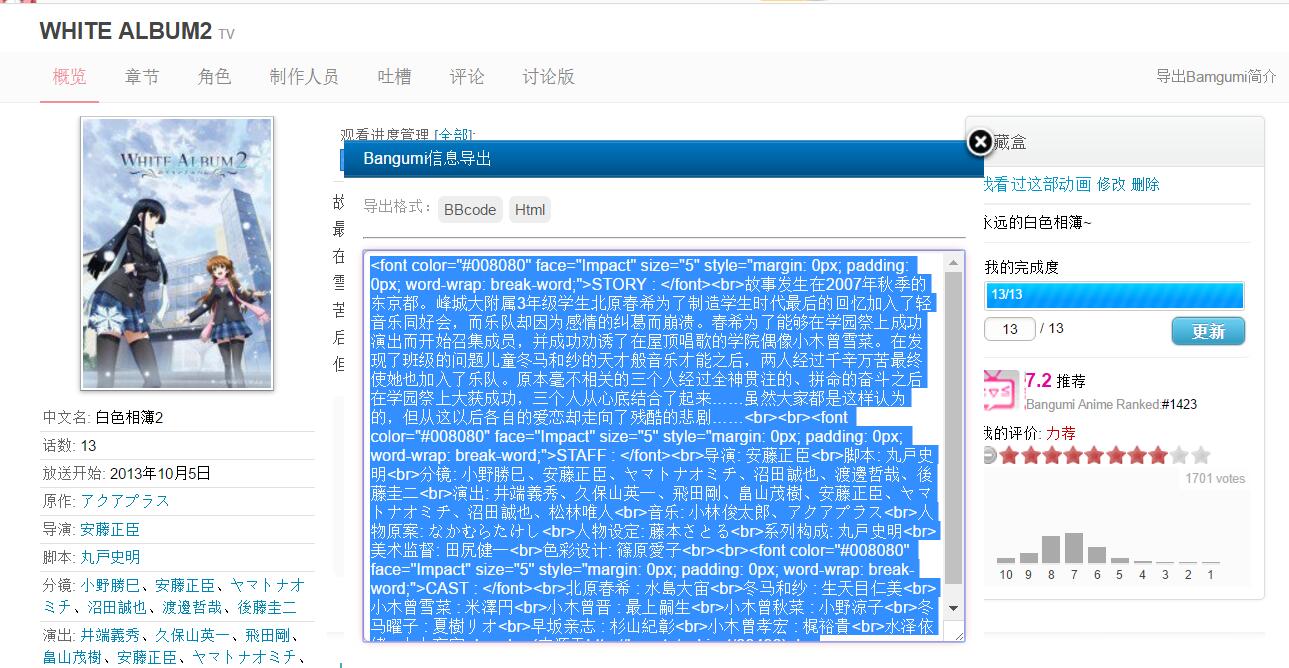
上面就是我预设出来的BBcode|HTML输出格式了~
上次一堆dalao老司机从农大到了我们学校,还吃了一顿薯条(参见北绿公众号文章:七级萌新去起八 by zfmwt)。
在吃前,我这样和大家说:“大家帮我画下more啊,我做cf要用的。”
然后,,,就这样,,,一把一把滴从地上捡了将近200把key(哭。。)直接爆了所有的key桶+剩余仓位。
然而还有没给我的一堆。。。(我真的没要这么多呀5555
这是我最后清算的仓库里的这几个起8po的key数
既然有那么多key,终于可以好好浪一下。然后就瞄中了隔壁的北林。
虽然自从感受到北绿的buff后,从一个合格的“多重党”退化成为xjbl份子(xjbl赛高!!!)但仍然本着最大化的精神,做出了下面这张第一版的规划:以我们学校 “树人”po为顶点,准备上了北林的所有po,以及一大堆我自已也看不清,不知道具体怎么实施的link。。
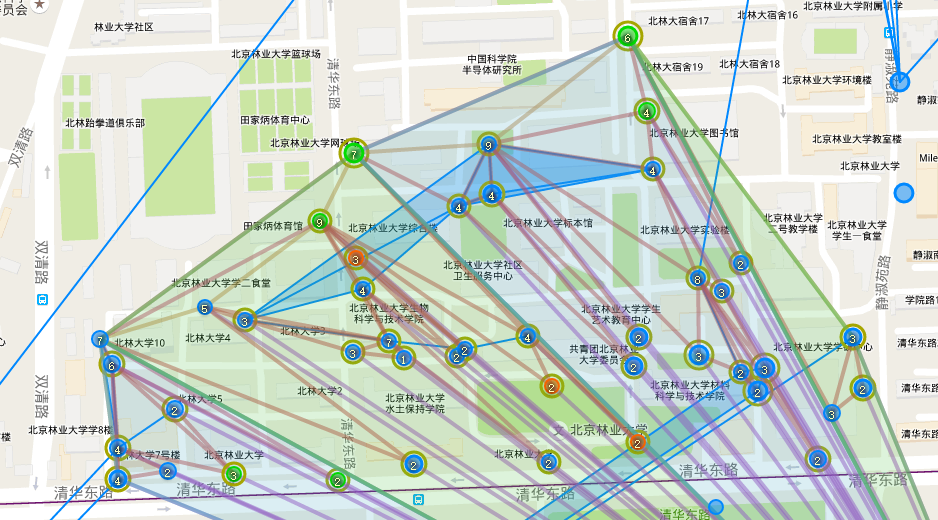
(这里图上标的是每个po可能的最大link数)
然后又分别在周三和周四(16、17号)去摸了一遍key。(应该逛了大概4圈左右。。
因为考虑到下周就要结束双倍ap活动了,所以原先就打算在本周五(11.25)的时候进行。然而在周四结束的时候,按照原先的规划仍然缺了部分顶点的key。于是便推出了修正计划2,同时加上了二十四孝的部分po组成了一个等腰梯形的field。
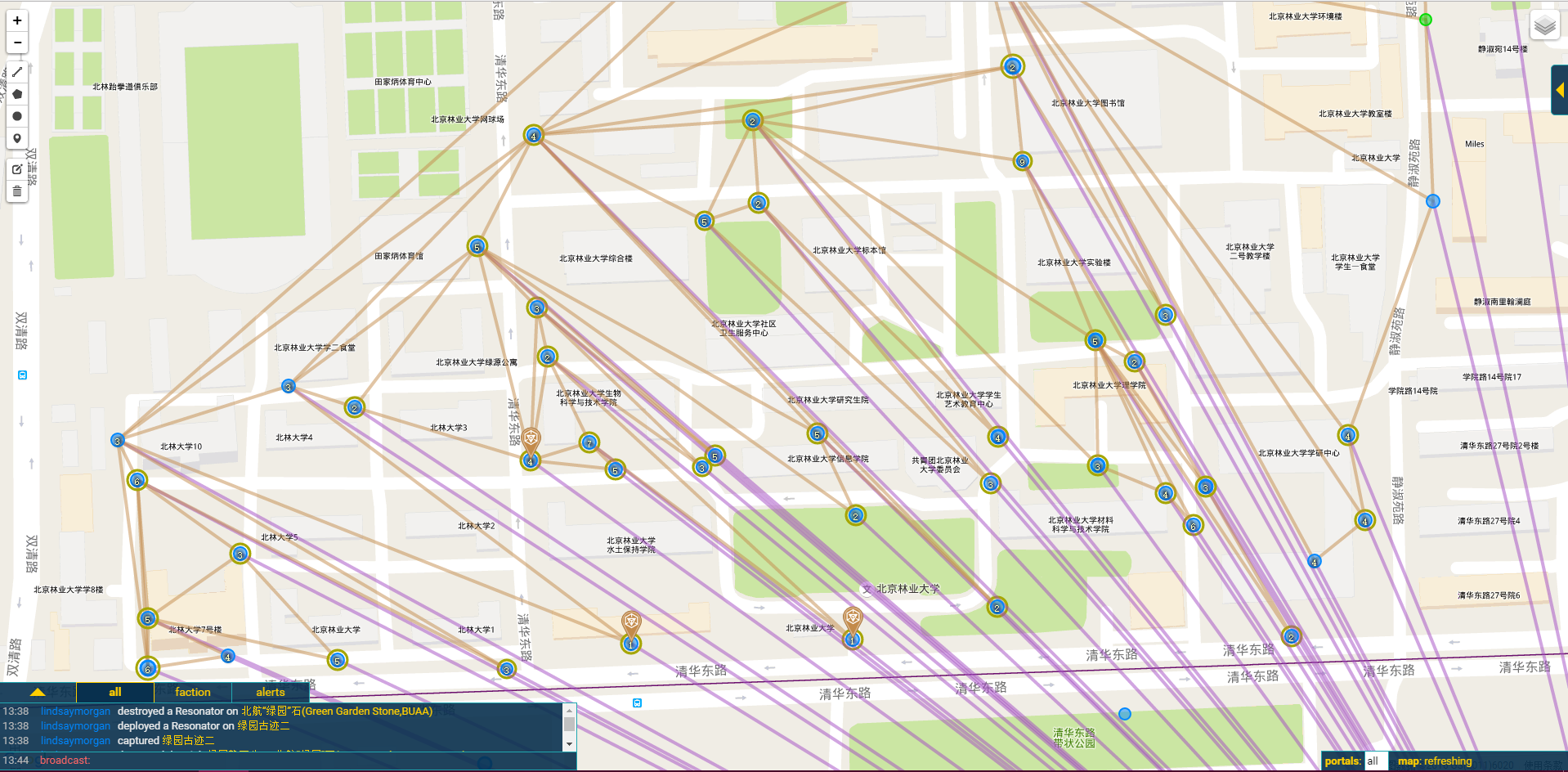
这个版本就比之前的好多了,而且只有几个po需要再摸1-2把key。
嗯,先贴图,在北林众多蓝军大佬闭上眼睛的情况下,如同规划一样,使用了北林所有的po,成功的做出了一个等腰梯形~
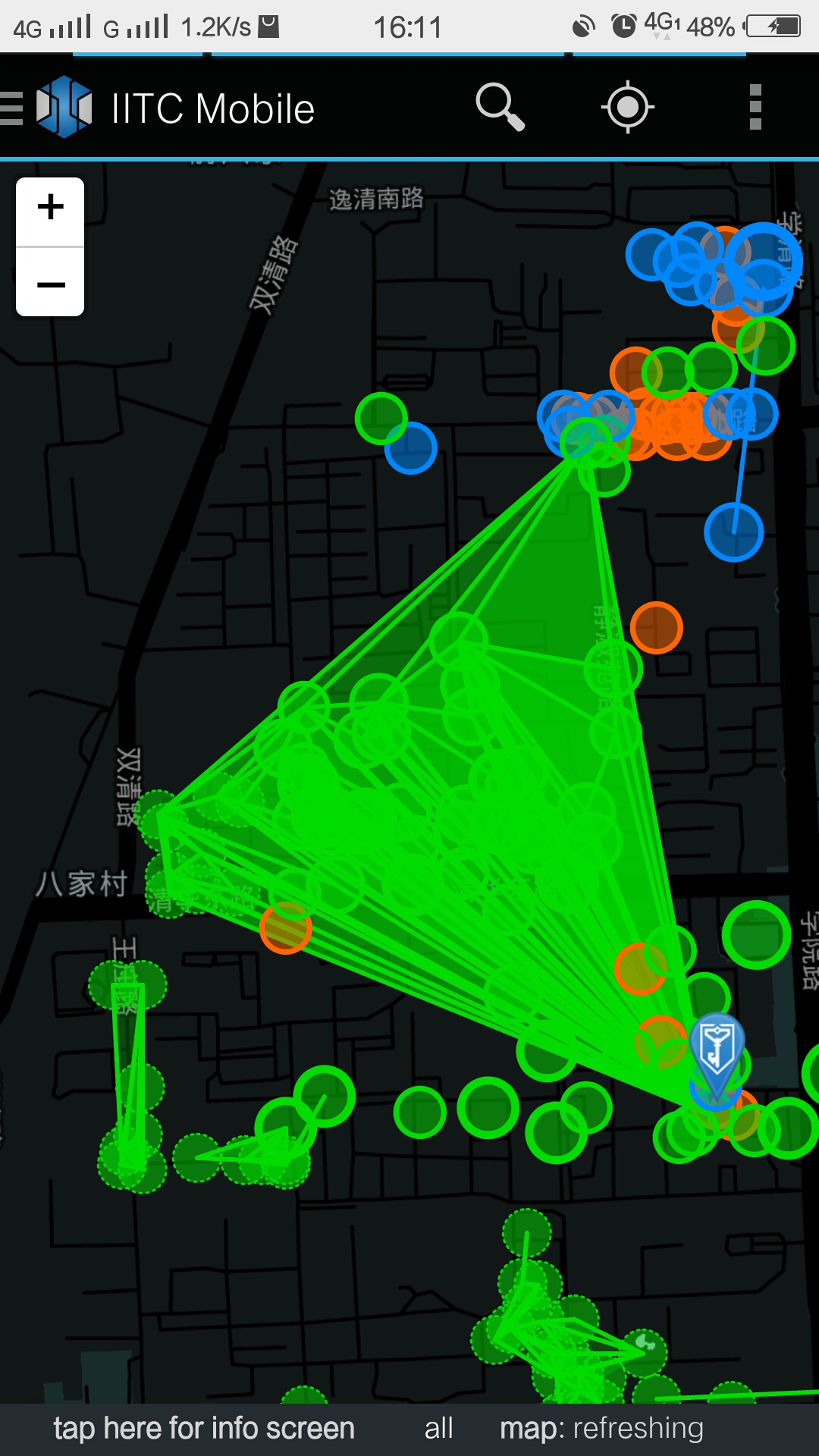
然后瞬间就被早已等待在顶点处的@Ox2333 给打掉了。。
然后是统计:
最后是小插曲:
key:上次起8po的 @LIql @JeffHugh @YukinoYUI @tomxie @hinate @bastianben @Loskiw @WilliamsLI @hiCarriew @BastianBen @Zfmwt 以及被我们吃掉的七名小伙伴;在得知我计划后@Cother @Determinant 赠与北林端点key,少了我很多摸key的功夫
清障:@Cother @Ox2333 在周五中午清理了北林和矿大内一堆block,使我成功的进行了这次计划
昨天翻LEB(相关文章链接:Exclusive Offer From Catalyst Host – Low End Box)的时候突然发现推了一款 Bandwidth 为 10TB,年付只要$12的VPS。。。
提供商是Catalyst Host: http://catalysthost.com/
提供的测试页面: http://lgdal.catalysthost.com/